Working with Modern Vulkan
Understanding Vulkan’s memory model
在Vulkan中,内存的管理与分配至关重要。但是Vulkan只负责决定分配内存的确切内存地址,除此以外所有的细节都由应用程序负责。也就是说,作为开发者,我们需要自行管理内存类型、内存大小、对齐方式以及任何子分配。这种设计方式为应用程序提供了更大程度的内存管理控制,允许开发者针对特定用途优化程序。
在本小节中,我们将会提供一些关于内存类型的基本信息,同时总结如何分配内存,并与资源绑定
Getting ready
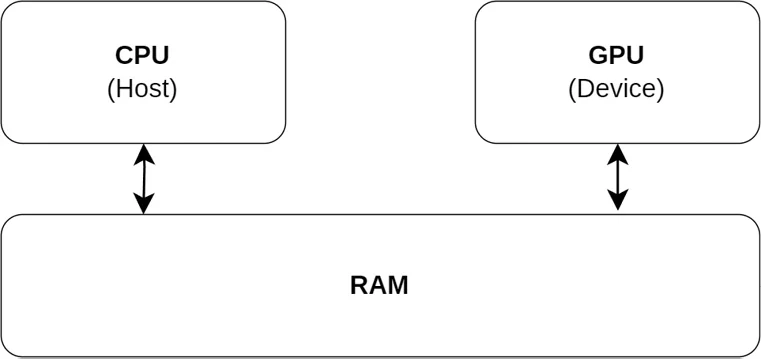
显卡分为两种,集成显卡与独立显卡。集成显卡会与CPU共享内存,也就是Host Memory,如下图所示:
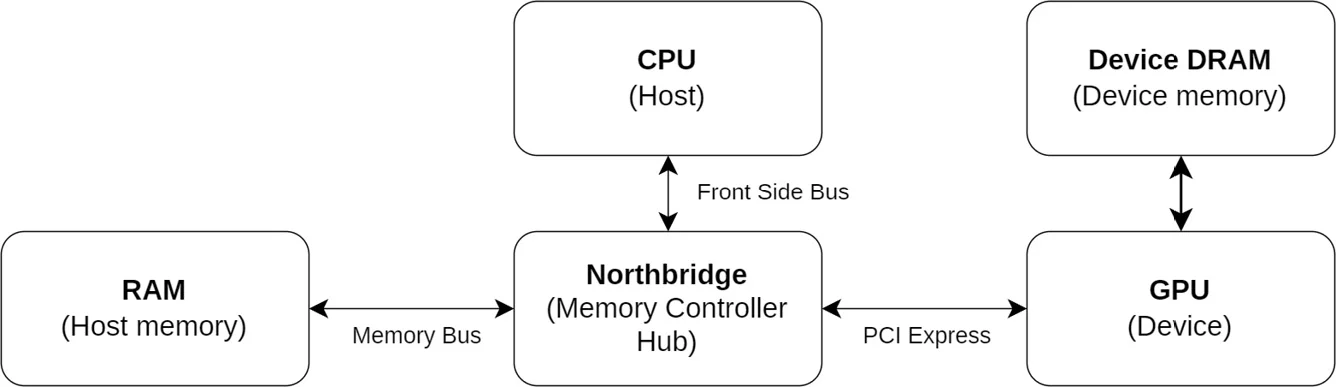
独立显卡有专属的内存,称为device memory,与CPU使用的内存host memory相互独立,如下图所示
Vulkan提供了三种不同类型的内存:
- Device-local memory:
- 为GPU的使用而优化的内存类型,是显卡的本地内存。它通常比主机可见内存更快,但是无法从CPU中访问。
- 通常来说,render target, storage images和buffer这些资源都存储在device-local内存中。
- Host-visible memory:
- CPU和GPU都可以访问
- 虽然它的速度通常比设备本地内存慢,但它可以有效地支持GPU与CPU之间的数据传输。
- 在非集成显卡上,GPU到CPU的数据读取会通过PCI-E通道进行,这种传输相对较慢,但对于需要频繁更新数据的场景来说,仍然是必要的。
- 这种内存常用于设置暂存缓冲区(staging buffers),将数据存储在这里以便之后转移到设备本地内存;同时也用于统一缓冲区(uniform buffers),这些缓冲区会不断地从应用程序更新数据。
- Host-coherent memory:
- 这类内存与主机可见内存类似,但能保证 GPU 和 CPU 之间的内存一致性。 这种类型的内存通常比设备本地内存和主机可见内存都要慢,但对于存储 GPU 和 CPU 都需要频繁更新的数据非常有用。
下图总结了上述三种类型的内存。
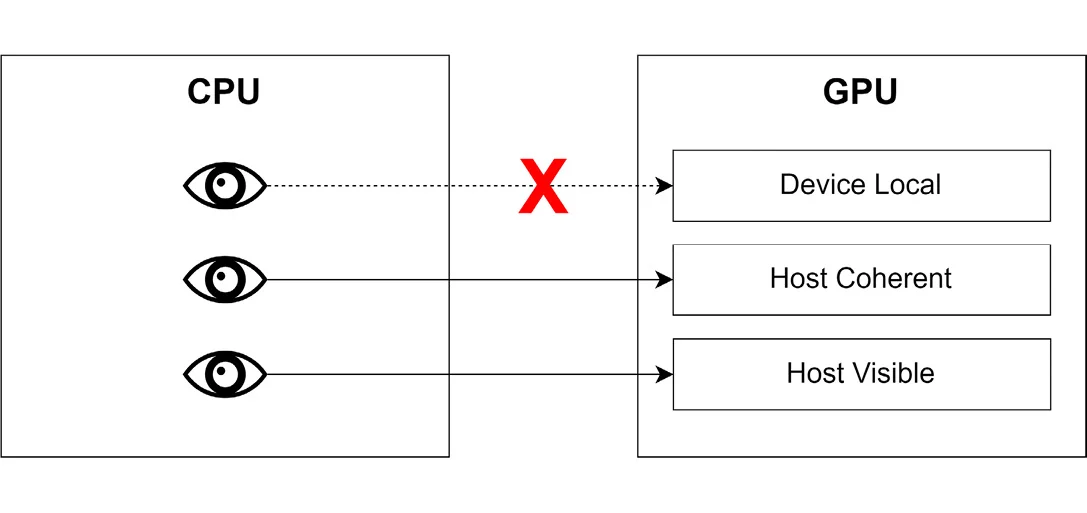
图像通常来说使用的是设备本地内存,而buffer可以是上述的任意一种类型
How to do it…
创建并将数据更新到一个buffer上的步骤通常是这样的:
- 使用
VkBufferCreateInfo结构体和函数vkCreateBuffer,创建一个VkBuffer对象 - 调用
vkGetBufferMemoryRequirements,根据buffer的属性获取相应的内存需求。比方说,设备可能会要求使用特定的对齐方式,这可能会影响为容纳buffer中的内存而分配的必要大小 - 创建一个
VkMemoryAllocateInfo结构体,指定为内存分配的大小以及内存的类型,然后再调用vkAllcateMemory执行实际的内存分配 - 调用
vkBindBufferMemory,将buffer对象与分配的内存绑定 - 将数据传递到buffer中,需要根据buffer类型分为两种情况
- 如果buffer对于主机是可见的,那么就可以通过
vkMapMemory将指针映射到buffer上,然后拷贝数据,最后在使用vkUnmapMemory取消映射。 - 如果是设备本地的buffer,我们需要先将数据拷贝到staging buffer中,然后再使用
vkCmdCopyBuffer,完成stage buffer到目标buffer的数据传递
- 如果buffer对于主机是可见的,那么就可以通过
可见,使用buffer的过程是较为复杂的,所以我们可以使用VMA这个开源库减少一些工作量。它为Vulkan中的内存管理提供了一种方便高效的方法。 它提供了一个高级接口,抽象了内存分配的复杂细节,让您从手动内存管理的负担中解脱出来。
Instantiating the VMA library
要使用VMA,我们首先需要创建一个VMA库实例,并在 VmaAllocator 类型的变量中存储一个句柄。
Getting ready
How to do it…
创建一个VMA库实例需要实例化两个不同的结构体,一个结构存储 VMA 查找其他函数指针所需的 API 函数指针,另一个结构提供物理设备、设备和用于创建分配器的实例
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
VKPhysicalDevice physicalDevice;
VkDevice device;
VkInstance isntance;
const uint32_t apiVersion = VK_API_VERSION_1_3;
const VmaVulkanFunctions vulkanFunctions =
{
.vkGetInstanceProcAddr = vkGetInstanceProcAddr,
.vkGetDeviceProcAddr = vkGetDeviceProcAddr,
#if VMA_VULKAN_VERSION >= 1003000
.vkGetDeviceBufferMemoryRequirenments = vkGetDeviceBufferMemoryRequirements,
.vkGetDeviceImageMemoryRequirements = vkGetDeviceImageRequirements,
#endif
};
VmaAllocator allocator = nullptr;
const VmaAllocatorCreateInfo allocaInfo =
{
.physicalDevice = physicalDevice,
.device = device,
.pVulkanFunctions = &vulkanFunctions,
.snstance = instance,
.vulkanApiVersion = apiVersion,
};
vmaCreateAllocator(&allocaInfo, &allocator);
分配器需要指向一些 Vulkan 函数的指针,这样它才能根据你想使用的功能工作。 在前面的例子中,我们只提供了分配和取消分配内存的最基本功能。 一旦使用 vmaDestroyAllocator 销毁上下文,就需要释放分配器。
Creating buffers
在Vulkan中,buffer是一个存储数据的连续内存块。这里的数据可以是顶点、索引、uniform,等等。
在 Vulkan 中,VkBuffer 对象本身确实只是一个元数据对象,它描述了缓冲区的类型、大小和用途等信息,但不直接包含数据。实际的数据存储在分配的内存中,通过 vkAllocateMemory 和 vkBindBufferMemory 函数将内存绑定到 VkBuffer 对象。
与buffer关联的内存是在buffer创建后才分配的。
下表总结了最重要的几个buffer的用法,以及对应的访问类型
| Buffer Type | Access Type | Uses |
|---|---|---|
| Vertex or Index | Read-only | |
| Uniform | Read-only | Uniform data storage |
| Storage | Read/write | Generic data storage |
| Uniform texel | Read/write | Data is interpreted as texels |
| Storage texel | Read/write | Data is interpreted as texels |
创建buffer很简单,但是在开始创建buffer之前,了解buffer的类型及其要求会有所帮助。在本小节中,我们将会实现一个创建buffer的模板
Getting ready
在本系列博客中,我们通过VulkanCore::Buffer类来管理Vulkan中的buffer,即创建buffer以及向buffer中更新数据的,此外还提供了从stagin buffer向设备本地的内存传递数据的函数,我们会在本篇博客中逐一介绍
How to do it…
通过VMA创建buffer很简单
我们需要提供标志(使用0作为标识值在大多数情况下都是正确的),以byte为单位的buffer的大小,buffer的用法。这些信息可以汇总在
VkBufferCreateInfo结构体中:1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
VkDeviceSize size; // the requested size of the buffer VmaAllocator allocator; // valid VMA Allocator VkUsageBufferFlags use; // transfer src/dsr/uniform/ssbo VkBuffer buffer; VkBufferCreateInfo createInfo = { .sType = VK_STRUCTURE_TYPE_BUFFER_CREATE_INFO, .pNext = nullptr, .flags = {}, .size = size, .usage = use, .sharingMode = VK_SHARING_MODE_EXCLUSIVE, .queueFamilyIndexCount = {}, .pQueueFamilyIndices = {}, };
还有一个额外的结构体:
1 2 3 4
const VmaAllocationCreaterFlagsBits allocCreateInfo = { VMA_ALLOCATION_CREATE_MAPPED_BIT, VMA_MEMORY_USAGE_CPU_ONLY };
然后,我们调用
vmaCreateBuffer获取一个buffer以及buffer分配的内存的句柄1 2 3
VmaAllocation allocation; // needs to live until the buffer is desctoried VK_CHECK(vmaCreateBuffer( allocator, &createInfo, &allocCreateInfo, &buffer, &allocation, nullptr));
这一步是可选的,但是有助于优化和debug
1 2
VmaAllocationInfo allocationInfo; vmaGetAllocationInfo(allocator, allocation, &allocationInfo);
Uploading data to buffers
将数据从应用程序中上传到GPU上的过程取决于buffer的类型。对于host-visible buffer来说,我们可以使用memcpy直接将数据拷贝到buffer上。而对于local-device buffer,我们需要一个对CPU和GPU均可见的staging buffer来完成数据的传递。
Getting ready
如果不是很理解,最好回顾一下Understanding Vulkan memory
How to do it…
我们分情况讨论
对于主机可见的内存,只需要vmaMapMemory获取指向目标buffer的指针,然后通过memcpy拷贝数据即可。这个操作是同步的,所以当memcpy返回后,我们就可以取消映射。此外,当我们创建host-visible buffer时,我们可以立即对其进行映射,保持映射状态,直至该buffer被销毁。这样的做法可以减少映射操作的内存开销。
1
2
3
4
5
6
7
8
9
10
VmaAllocator allocator; // valid VMA allocator
VmaAllocation allocation; // valiad VMA allocation
void* data; // data to be uploaded
size_t size; // size of data in bytes
void* map = nullptr;
VK_CHECK(vmaMapMemory(allocator, allocation, &map));
memcpy(map, data, size);
vmaUnmapMemory(allocator, allocation);
VK_CHECK(vmaFlushAllocation(allocator, allocation, offset, size));
对于设备本地的内存,我们需要先将数据拷贝到staging buffer上,然后再通过vkCmdCopyBuffer将数据从staging buffer拷贝到我们的目标buffer中,这一步操作需要使用到command buffer。过程如下图所示:
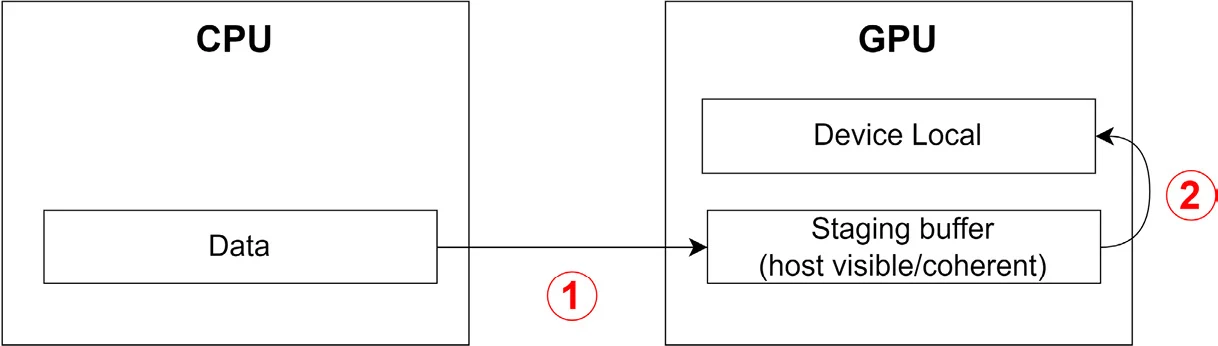
1
2
3
4
5
6
7
8
VkDeviceSize srcOffset;
VkDeviceSize dstOffset;
VKDeviceSize size;
VkCOmmandBuffer commandBuffer; // Valid Command Buffer
VkBuffer stagingBuffer;
VkBuffer buffer; // a device-local buffer
VkBufferCopy region(srcOffset, dstOffset, size);
VkCmdCopyBuffer(commanBuffer, stagingBuffer, buffer, 1, ®ion);
Creating a staging buffer
创建一个staging buffer的过程与创建一个普通buffer的过程类似,只是我们需要指定一个标志,表示此buffer是主机可见的。
Getting ready
在Creating buffers这一小节中,我们已经了解了如何创建一个buffer对象,所以本小节我们只需要了解创建staging buffer所需要的标志和参数即可
How to do it…
我们需要将VkBufferCreateInfo::usage包含VK_BUFFER_USAGE_TRANSFER_SRC_BIT,因为在vkCmdCopyBuffer这个命令中,staging buffer会作为数据的来源
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
const VkBufferCreatInfo stagingBufferInfo =
{
.sType = VK_STRUCTURE_TYPE_BUFFER_CREATE_INFO,
.size = size,
.usage = VK_BUFFER_USAGE_TRANSFER_SRC_BIT,
};
const vmaAllocationCreateInfo stagingAllocationCreateInfo =
{
.flags = VMA_ALLOCATION_CREATE_HOST_ACCESS_SEQUENTIAL_WRITE_BIT | VMA_ALLOCATION_CREATE_MAPPED_BIT,
.usage = VMA_MEMORY_USAGE_CPU_ONLY,
};
const VmaAllocationCreateFlagsBits allocCreateInfo =
{
VMA_ALLOCATION_CREATE_MAPPED_BIT,
VMA_MEMORY_USAGE_CPU_ONLY,
};
VmaAllocation allocation;
VK_CHECK(vmaCreateBuffer(allocator, &stagingBufferInfo, &allocCreateInfo, &buffer, &allocation, nullptr);
How to avoid data races using ring buffers
当buffer需要每帧更新时,我们就可能面临数据竞赛的风险,如下图所示
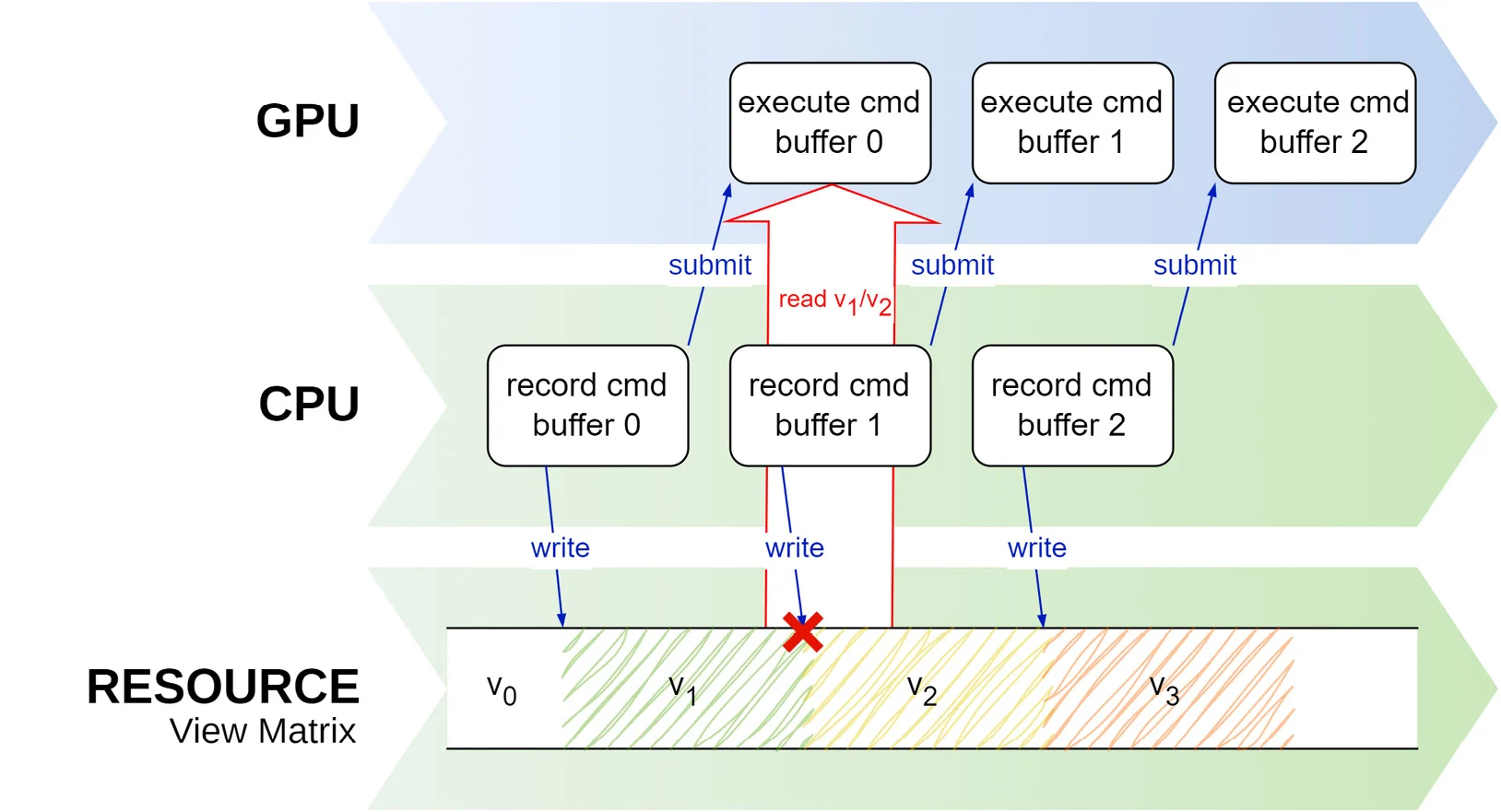
数据竞赛指的是,程序中的多个线程同时处理一个共享的数据点,并且至少有一个线程在执行写入的操作。由于操作顺序不可预测,这种并发访问会导致不可预见的行为。
以存储mvp矩阵的uniform buffer为例,这个buffer会在每帧更新。此时,就有可能发生当应用程序试图更新MVP矩阵时,GPU还在访问其中的数据来完成渲染的情况。
Getting ready
目前来说,处理同步是Vulkan中最为复杂的一部分。如果我们在程序中滥用semaphore,fence或barrier等同步元素,就有可能导致无法充分利用Vulkan中CPU和GPU并行运行的能力。
所以,在继续之前,最好回顾Understanding synchronization in the swapchain这一小节。
我们会在EngineCore::RingBuffer这类中实现环形buffer,该buffer具有可配置的子buffer数量,所有的子buffer都是主机可见的,同时能够一直位置映射状态,以便于访问
How to do it…
避免数据竞赛的方法有很多,但最简单的方法是建立一个环形buffer,它包含了数个buffer(或其他任何资源),数量与渲染管线中同时处理的帧数量相等。下图显示了使用两个buffer时的情况。一旦第一个command buffer提交,然后在GPU中处理时,应用程序就可以自由地处理其中没有被GPU使用的buffer
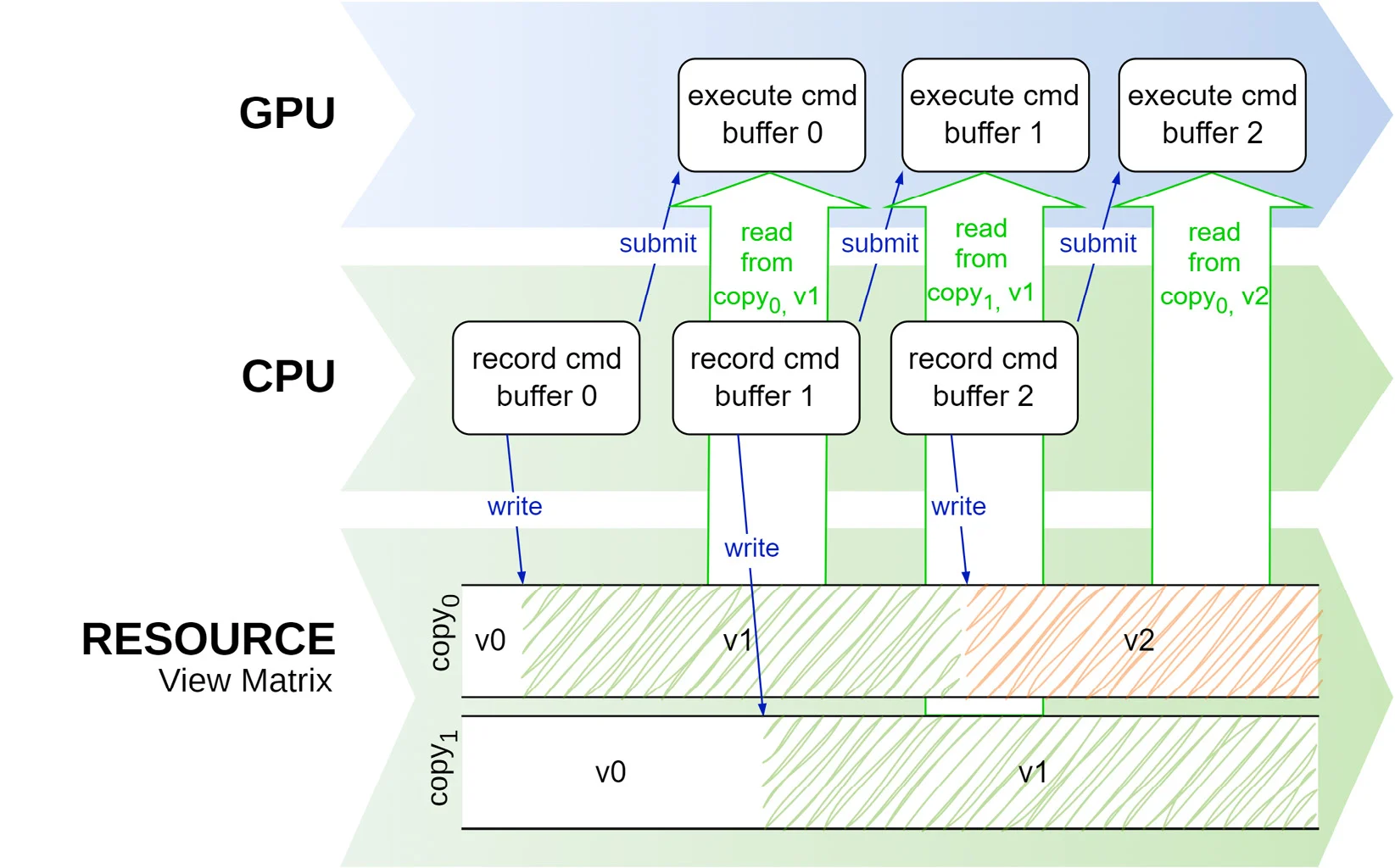
虽然这是一个简单的方案,但是也存在一些注意事项。如下图所示,环形缓冲区包含了多个子分配(sub-allocations),每个子分配分别存储了视图矩阵、模型矩阵、视口矩阵。这个缓冲区用于存储不同帧数据的多个副本,每个副本都初始化为单位矩阵。在渲染管线中,每一帧的缓冲区可能会部分更新,例如只更新模型矩阵或者视口矩阵,而不更新其他矩阵。
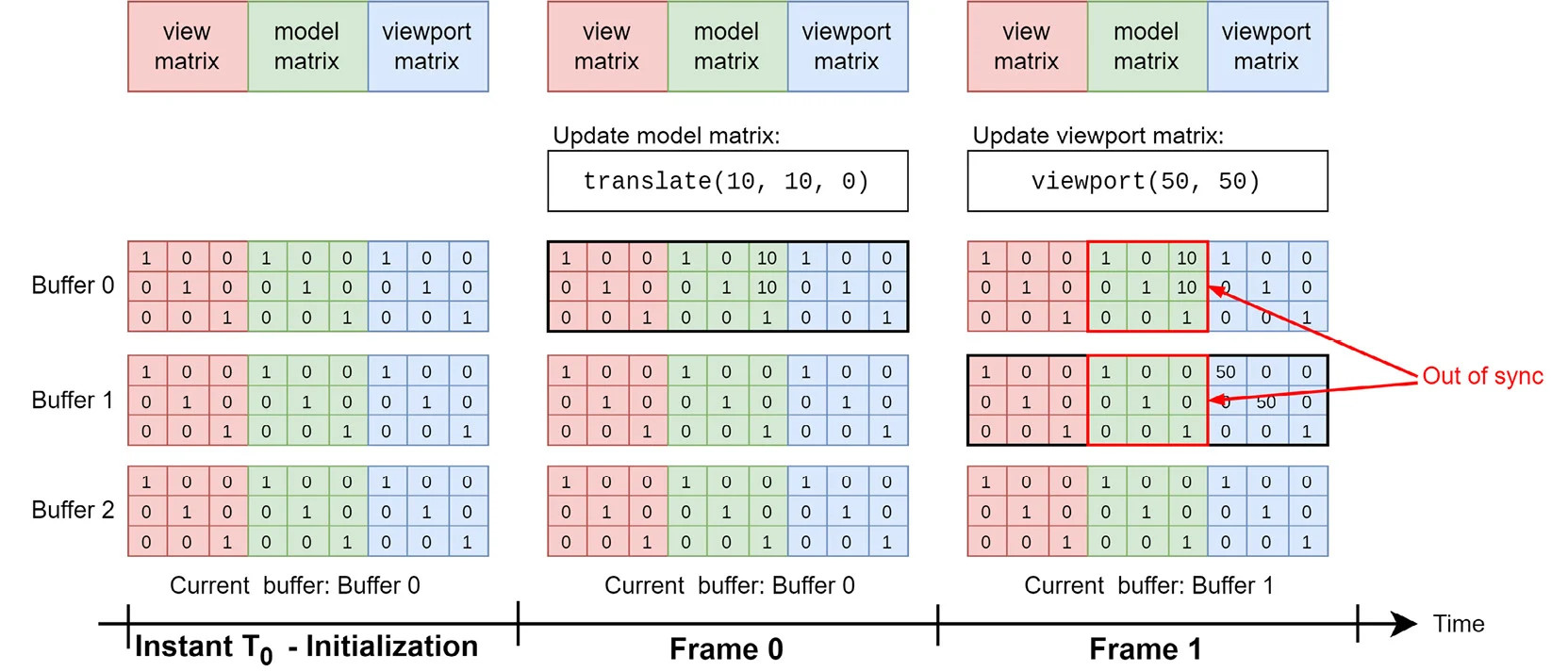
我们来逐帧解释:
初始化(T0 时刻): 在缓冲区创建时,Buffer 0、Buffer 1 和 Buffer 2 中的所有矩阵都被初始化为单位矩阵。
Frame 0(第一帧): 在第一帧中,Buffer 0 是当前使用的缓冲区。模型矩阵被更新为包含一个平移变换 (10, 10, 0),因此 Buffer 0 的模型矩阵变为 [10, 10, 0]。但此时,视图矩阵和视口矩阵保持不变。
Frame 1(第二帧): 在第二帧中,环形缓冲区从 Buffer 0 切换到 Buffer 1,并且视口矩阵被更新,视口矩阵的值变为 [50, 50]。然而,由于 Buffer 1 是初始化的单位矩阵,当只更新视口矩阵时,Buffer 1 中的模型矩阵和视图矩阵仍然保持单位矩阵。这就导致了不同步问题——在 Buffer 1 中,模型矩阵没有继承 Buffer 0 中的更新(translate(10, 10, 0)),从而与 Buffer 0 中的状态不一致。
最终,这种不同步会导致渲染时使用错误的模型变换,从而产生渲染错误。为了解决部分更新带来的不同步问题,每次更新一个缓冲区时,首先需要将前一个缓冲区的内容拷贝到当前缓冲区中。例如,在 Frame 1 中更新视口矩阵时,应该首先将 Buffer 0 的内容复制到 Buffer 1 中,然后再更新 Buffer 1 的视口矩阵。这确保了所有子分配(矩阵)始终是同步的,不会丢失之前的任何更新。
Setting up pipeline barriers
在Vulkan中,处理command buffer时,可以对命令进行重新排序,但是要受到某些限制。这就是所谓的command buffer重排序,它允许驱动程序优化命令的执行顺序,从而有助于提高性能。
好在 Vulkan 提供了一种称为管道屏障的机制,可以确保以正确的顺序执行相关命令。 它们用于明确指定命令之间的依赖关系,防止它们被重新排序,以及它们在哪些阶段可能会重叠。
Getting ready
考虑下面两个依次发出的调用,第一个命令写入到一个颜色附件中,第二个命令需要从上个上一个颜色附件中读取颜色。
1
2
vkCmdDraw(...); // draws into color attachment 0
vkCmdDraw(...); // reads from color attachment 0
下图可以帮助我们理解GPU是如何处理这两个命令的。如图,命令是从上向下处理,而渲染管线的进程是从左到右。在这里,时钟周期是一个宽泛的术语,因为处理过程可能需要多个时钟周期,但是已经可以大致为我们表述清楚命令执行的先后顺序了。

在这个例子中,第二个vkCmdDraw从C2开始执行,晚于第一个vkCmdDraw。但是从图中可以看出,C1作为时间偏差是不够的,第二个vkCmdDraw需要在片段着色器阶段读取来自第一个vkCmdDraw要写入的颜色附件,但是第一个vkCmdDraw还在Early Fragment的阶段。可以看出,如果没有设置同步,就会导致这样的数据竞赛发生。
管线屏障是一种指令,它被记录在命令缓冲区中,用于控制 GPU 命令的执行顺序。它指明了哪些管线阶段必须完成,确保在执行后续命令之前,前面的命令已经完全执行。这对于确保资源的一致性和防止数据冲突非常重要。同时,它定义了两个同步范围:
- 第一同步范围(first synchronization scope):在管线屏障之前记录的所有命令都属于这个范围。也就是说,在这些命令执行完毕之前,管线屏障会确保后续的操作不会开始。
- 第二同步范围(second synchronization scope):管线屏障之后记录的所有命令都属于这个范围。这些命令只能在第一范围中的命令执行完毕后才会被处理。
此外,管线屏障允许开发者指定更精确的条件,控制第二个作用域中的命令在何种情况下开始执行。也就是说,可以选择哪些命令需要等待第一作用域中的命令完成。第二个作用域中的命令不必完全等到第一个作用域中的所有命令都执行完毕,只要满足管线屏障中定义的特定条件,它们就可以立即开始处理。这种机制提高了渲染和计算的并行性,使得 GPU 资源的利用更加高效。
回到我们的例子中,第一个作用域中的第一个指令需要写入颜色附件后,第二个绘制调用才能访问该附件。但是第二个绘制调用不需要等到颜色附件被写入后才开始,而是可以在调用时就即可执行,只要它的片段着色器阶段发生在颜色附件写入完成后即可 ,如下图所示:

Vulkan提供了三种类型的屏障
- 内存屏障:全局性的屏障,可以应用于第一范围和第二范围的所有指令
- buffer内存屏障:只适用于访问buffer部分内容的命令
- 图像内存屏障:只适用于访问图像子资源的命令。这是一种相当重要的屏障,它可以用在图像布局的转换上。例如,在生成mipmap时,从一个层级blit到下一个层级,不同的层级之间需要设置正确的布局:前一个层级的布局需要为
VK_IMAGE_LAYOUT_TRANSFER_SRC_OPTIMAL,表示该层级需要被读取,而下一个层级的布局需要为VK_IMAGE_LAYOUT_TRANSFER_DST_OPTIMAL,表示作为写入的对象。
How to do it…
管线屏障通过vkCmdPienlineParrirer命令记录,下面这段代码展示了如何为什么前面提到的例子创建屏障
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
const VkImageSubresourceRange subresource =
{
.aspectMask = .baseMipLevele = 0,
.levelCount = VK_REMAINING_MIP_LEVElS,
.baseArrayLayer = 0,
.layerCount = 1,
};
const VkImageMemoryBarrier imageBarrier =
{
.sType = VK_STRUCTURE_TYPE_IMAGE_MEMORY_BARRIER,
.srcAccessMask = VK_ACCESS_2_COLOR_ATTACHMENT_WRITE_BIT_KHR,
.dstAccessMask = VK_ACCESS_2_SHADER_READ_BIT_KHR,
.oldLayout = VK_IMAGE_LAYOUT_ATTACHMENT_OPTIMAL,
.newLayout = VK_IMAGE_LAYOUT_READ_ONLY_OPTIMAL,
.srcQueueFamilyIndex = VK_QUEUE_FAMILY_IGNORED,
.dstQueueFamilyIndex = VK_QUEUE_FAMILY_IGNORED,
.image = image,
.subresourceRange = &subresource,
};
vkCmdPipelineBarrire(
commandBuffer,
VK_PIPELINE_STAGE_COLOR_ATTACHMENT_OUTPUT_BIT,
VK_PIPELINE_STAGE_FRAGMENT_SHADER_BIT,
0, 0, nullptr, 0, nullptr, 1, &memoryBarrire);
最后,我们需要在两个绘制调用之间记录屏障
1
2
3
vkCmdDraw(...); // draws into color attachment 0
vkCmdPipelineBarrier(...);
vkCmdDraw(...); // reads from color attachment 0
Creating image(textures)
绝大多数图像用于存储二位数据。与buffer不同,图像具有优化内存布局位置的优势。这是因为GPU中有固定功能的纹理单元或者采样器,能够从图像中读取纹理数据,并应用过滤或其他操作生成最终的颜色值。图像可以有不同的格式,如RGB,RGBA,BRGA等
与buffer类似,在Vulkan中,图像对象只是元数据,它的数据单独存储,如下图所示
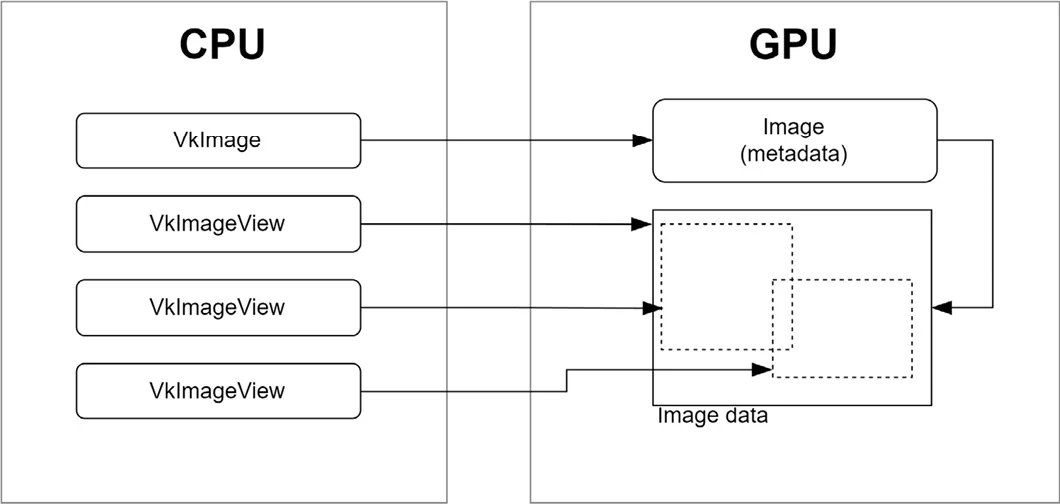
Vulkan中的图像不可以直接访问,而是需要通过image view。image view指定了子资源范围(如颜色或深度),mip级别,数组层访问。
图像有一个至关重要的性质:图像的布局。它用于指定Vulkan中的图像的预期用途,例如是否应该将其用作传输操作的源或目标,或者渲染的颜色附件或深度附件,或者用作着色器的读写资源。设置正确的图像布局非常重要,因为它能够确保GPU根据预期用途高效地访问和处理图像数据,使用错误的图像布局会导致性能问题或渲染伪像,并可能导致未定义的行为。
常见的图像布局包括:
VK_IMAGE_LAYOUT_UNDEFINEDVK_IMAGE_LAYOUT_COLOR_ATTACHMENT_OPTIMALVK_IMAGE_LAYOUT_DEPTH_STENCIL_ATTACHMENT_OPTIMALVK_IMAGE_LAYOUT_SHADER_READ_ONLY_OPTIMAL
另外值得一提的是,图像的布局转换是vkCmdPipeBarrier的一部分
在本小节中,我们将了解如何创建一个VkImage对象
Getting ready
在本系列博客中,我们将复杂的图像和VkImageView的管理封装在VulkanCore::Texture类中,还有一些其他的细节,可以在源码中查看。
How to do it…
填充VkImageCreateInfo的代码这里就省略了
我们声明一个VmaAllocationCreateInfo,表示这个图像是一个device-only的图像
1
2
3
4
5
6
7
const VmaAllocaitionCreateInfo allocInfo =
{
.flags = VMA_ALLOCATION_CREATE_DEDICATED_MEMORY_BIT,
.usage = VMA_MEMORY_USAGE_AUTO_PREFER_DEVICE,
.priority = 1.0f,
};
VK_CHECK(vmaCreateImage(vmaAllocator, &imageInfo, &allocCreateInfo, &image, &vmaAllocation, nullptr));
另外,创建VkImageView的过程较为简单直白,本篇博客就直接忽略了
Creating a sampler
Vulkan中,sampler是一个较为复杂的对象。它是shader执行与图像数据之间的重要桥梁,还管理了图像的插值,过滤,寻址模式,mipmapping等
Getting ready
我们将sampler的创建与管理封装在VulkanCore::Sampler中。
How to do it…
sampler的属性定义了图像在管线(通常是shader中)的解释方式,创建sampler的也很简单,实例化一个VkSamplerCreateInfo结构体,并调用vkCreateSampler。这里就不再展示相关代码了
Providing shader data
在 Vulkan 中,从应用程序中提供将在着色器中使用的数据是最复杂的方面之一,需要按照正确的顺序(并使用正确的参数)完成几个步骤。
Getting ready
在shader中所使用的资源是需要通过关键字layout与修饰符set、binding指定,例如
1
2
3
4
5
6
layout (set = 0, binding = 0) uniform Transforms
{
mat4 model;
mat4 view;
mat4 proj;
} MVP;
每个资源都通过一个binding表示,set则是一组binding的集合。需要注意的是,一个binding不一定以表示一个资源,它也可以表示一个同一类型的资源的数组。
How to do it…
将资源提供给shader包含了一系列步骤:
- 通过描述符集布局,指定
set与binding。- 这一步并不与实际的资源关联,我们只是指定了
set中binding的数量与类型
- 这一步并不与实际的资源关联,我们只是指定了
- 构建一个管线布局,用于描述管线中会使用到哪些
set - 创建一个描述符池,用于分配描述符集实例。此外,描述符池可以根据不同的
binding类型,如纹理、采样器、SSBO 和统一缓冲区等,确定能够提供的绑定数量。 - 通过函数
vkAllocateDescriptorSets,从描述符池中分配描述符集。 - 通过
vkUpdateDescriptorSets,将资源绑定到binding上- 这里是我们将
set、binding与实际的资源关联的地方
- 这里是我们将
- 在渲染过程中,通过
vkCmdBindDescriptorSet将描述符集与其binding绑定到管线上- 这里,管线中的shader就可以通过指定的
set与binding访问资源了
- 这里,管线中的shader就可以通过指定的
接下来,我们会了解每一步的具体实现
Specifying descriptor sets with descriptor set layouts
我们以下面这个shader为例
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
#version 460 core
struct Vertex
{
vec3 pos;
vec3 normal;
vec2 uv;
};
layout(set = 0, binding = 0) uniform Transform
{
mat4 model;
mat4 view;
mat4 proj;
} MVP;
layout(set = 1, binding = 0) uniform texture2D textures[];
layout(set = 1, binding = 1) uniform sampler samplers[];
layout(set = 2, binding = 0) readonly buffer Vertices
{
Vertex vertices[];
};
这个shader需要三个set,所以我们需要创建三个描述符集。
Gettting ready
我们通过VulkanCore::Pipeline这个类创建、存储和管理描述符集与binding。
在Vulkan中,我们可以将描述符集理解为一个存储shader所使用的资源(例如buffer,texture,sampler)的容器。
而绑定则可以理解为将这些描述符集与特定的shader阶段相关联的过程。通过绑定,shader与资源可以在渲染过程中无缝地进行交互。
How to do it…
我们通过结构体vkDescriptorSetLayout 来指定一个描述符集的binding数量与类型。而每个binding则又是通过VkDescriptorSetLayoutBinding结构体来指定的。它们之间的关系可以通过下面表示
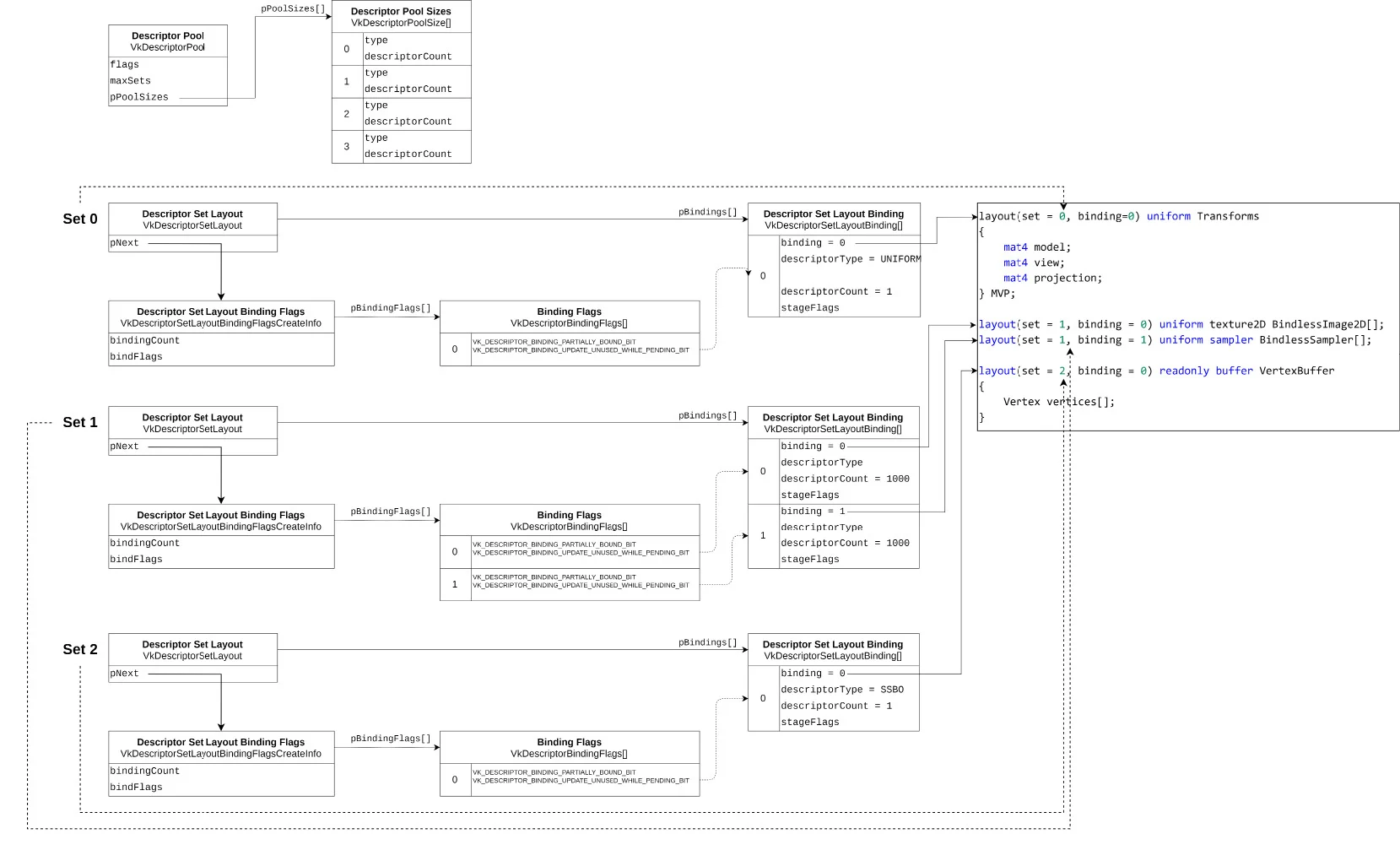
下面这段代码展示了如何指定set = 1中的两个binding
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
constexpr uint32_t kMaxBindings = 1000;
const VkDescriptorSetLayoutBinding textureBinding =
{
.binding = 0,
.descriptorType = VK_DESCRIPTOR_TYPE_SAMPLED_IMAGE,
.descriptorCount = kMaxBindings,
.stageFlags = VK_SHADER_STAGE_VERTEX_BIT,
};
const VkDescriptorSetLayoutBinding samplerBinding =
{
.binding = 1,
.descriptorType = VK_DESCRIPTOR_TYPE_SAMPLER,
.descriptorCount = kMaxBindings,
.stageFlags = VK_SHADER_STAGE_VERTEX_BIT,
};
struct DescriptorSet
{
uint32_t set;
std::vector<VkDescriptorSetLayoutBinding> bindings;
};
std::vector<DescriptorSet> descriptorSets =
{
{
.set = 0,
.bindings = {textureBinding, samplerBinding},
},
};
代码展示的思路很清晰,但是有一点需要我们留意,我们为VkDescriptorSetLayoutBinding指定的descriptorCount是一个很大的值,这是因为对应的shader资源是一个数组,我们需要填充一个较大的值,才能确保足以容纳对应的数组中的元素数量。
然后,我们就可以使用我们自定义的结构体DescriptorSet创建对应的描述符集了
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
constexpr VkDescriptorBindingFlags flags =
VK_DESCRIPTOR_BINDING_PARTIALLY_BOUND_BIT |
VK_DESCRIPTOR_BINDING_UPDATE_UNUSED_WHILE_PENDING_BIT;
for (size_t setIndex = 0; const auto& set : descriptorSets)
{
std::vector<VkDescriptorBindingFlags> bindingFlags(set.bindings.size(), flags);
const VkDescriptorSetLayoutBindingFlagsCreateInfo bindingFlagsInfo =
{
.sType = VK_STRUCTURE_TYPE_DESCRIPTOR_SET_LAYOUT_BINDING_FLAGS_CREATE_INFO,
.bindingCount = static_cast<uint32_t>(set.bindings.size()),
.pBindingFlags = bindingFlags.data(),
};
const VkDescriptorSetLayoutCreateInfo layoutInfo =
{
.sType = VK_STRUCTURE_TYPE_DESCRIPTOR_SET_LAYOUT_CREATE_INFO,
.bindingCount = static_cast<uint32_t>(set.bindings.size()),
.pBindings = set.bindings.data(),
.pNext = &bindingFlagsInfo,
};
VkDescriptorSetLayout layout;
VK_CHECK(vkCreateDescriptorSetLayout(device, &layoutInfo, nullptr, &layout));
}
Passing data to shaders using push constants
推送常量是另一种向shader传递数据的方法,且具有简单高效的特性。但是Vulkan通常会限制传递的常量的大小为128比特
Getting ready
相关代码在VulkanCore::Pipeline这个类中
How to do it…
常量在shader中的声明如下,每个shader中最多有一个常量块
1
2
3
4
layout (push_constant) uniform Transforms
{
mat4 model;
} PushConstants;
1
2
3
4
5
6
7
const VkPushConstantRange range = {
.stageFlags = VK_SHADER_STAGE_VERTEX_BIT,
.offset = 0,
.size = 64,
};
std::vector<VkPushConstantRange> pushConsts;
pushConsts.push_back(range);
常量的推送直接记录在Command buffer中,且不会像其他资源那样容易出现同步问题。
Creating a pipeline layout
在Vulkan中,应用程序需要负责VkPipelineLayout对象的创建与销毁。我们使用定义了binding与set布局的结构体指定VkPipelineLayout
Getting ready
在VulkanCore::Pipeline类中,VkPipelineLayoutCreateInfo会根据我们提供的binding与set的信息自行创建
How to do it…
在创建VkPipelineLayout时,我们需要准备描述符集布局和推送的常量的相关信息
1
2
3
4
5
6
7
8
9
10
11
12
13
std::vector<VkDescriptorSetLayout> descriptorSetLayouts;
const VkPipelineLayoutCreateInfo pipelineLayoutInfo =
{
.sType = VK_STRUCTURE_TYPE_PIPELINE_LAYOUT_CREATE_INFO,
.setLayoutCount = static_cast<uint32_t>(descriptorSetLayouts.size()),
.pSetLayouts = descriptorSetLayouts.data(),
.pushConstantRangeCount = !pushConstants.empty() ? uint32_t(pushConstants.size()) : 0,
.pPushConstantRanges = !pushConstants.empty() ? pushConstants.data() : nullptr,
};
VkPipelineLayout pipelineLayout;
VK_CHECK(vkCreatePipelineLayout(device, &pipelineLayoutInfo, nullptr, &pipelineLayout));
Creating a descriptor pool
描述符池包含它可以提供的最大数量的描述符,这些描述符按绑定类型分组。例如,如果同一set的两个binding各自需要一个图像,那么描述符池必须至少提供两个描述符。
Getting ready
相关代码封装在 VulkanCore::Pipeline::initDescriptorPool() 方法中
How to do it…
创建描述符池很简单,我们只需要提供一个指定资源的binding类型与最大数量的列表即可
1
2
3
4
constexpr uint32_t swapchainImageCount = 3;
std::vector<VkDescriptorPoolSize> poolSize;
poolSize.emplace_back(VkDescriptorPoolSize{VK_DESCRIPTOR_TYPE_SAMPLED_IMAGE, swapchainImageCount * kMaxBindings});
poolSize.emplace_back(VkDescriptorPoolSize{VK_DESCRIPTOR_TYPE_SAMPLER, swapchainImageCount * kMaxBindings});
创建的过程就不展示了,比较简单
Allocating descriptor sets
当我们创建好描述符池后,我们就可以从其中分配描述符集了
Getting ready
相关代码封装在VulkanCore::Pipeline::allocateDescriptors()函数中。我们需要提供要创建的描述符集的数量,以及每个描述符集所需的binding数量。
How to do it…
分配描述符集很简单,我们只需要填充VkDescriptorSetAllocateInfo结构体,并调用vkAllocateDescriptorSets即可
具体代码暂时不展示了
Updating descriptor sets during rendering
分配描述估计时,并不会与资源进行关联,我们在本小节中了解如何更新描述符集
Getting ready
在VulkanCore::Pipeline类中,我们根据资源类型的不同,提供了对应类型的更新描述符集的函数
updateSamplersDescriptorSetsupdateTexturesDescriptorSetsupdateBuffersDescriptorSets
How to do it…
在Vulkan中,我们通过vkUpdateDescriptorSets函数将一个描述符集与资源关联在一起。每次调用vkUpdateDescriptorSets,我们可以更新一个或多个set中的一个或多个binding。
在我们了解如何更新描述符之前,我们不妨先了解一下如何更新一个单一的binding
通过一个binding,我们可以关联的资源包括:
- texture
- texture array
- sampler
- sampler array
- buffer
- buffer array
当关联图片或采样器时,我们使用VkDescriptorImageInfo结构体,当关联buffer时,我们使用VkDescriptorBufferInfo结构体。当我们填充好这些结构体后,我们就可以使用VkWriteDescriptorSet结构体,通过一个binding将它们绑定在一起。
我们来看下面这个shader,并以它为例子
1
2
3
4
5
6
layout (set = 1, binding = 0) uniform texture2D textures[];
layout (set = 1, binding = 1) uniform sampler samplers[];
layout (set = 1, binding = 2) readonly buffer VertexBuffer
{
Vertex vertices[];
} vertexBuffer;
当我们想要更新texture[]数组时,我们需要为每个数组中的元素填充一个VkDescriptorImageInfo,然后将所有的VkDescriptorImageInfo写入VkWriteDesciptorSet中。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
VkImageView imageViews[2]; // valid image view objects
VkDescriptorImageInfo textureInfos[] =
{
VkDescriptorImageInfo
{
.imageView = imageViews[0],
.imageLayout = VK_IMAGE_LAYOUT_SHADER_READ_ONLY_OPTIMAL,
},
VkDescriptorImageInfo
{
.imageView = imageViews[1],
.imageLayout = VK_IMAGE_LAYOUT_SHADER_READ_ONLY_OPTIMAL,
},
}
const VkWriteDescriptorSet textureWriteDecsSet =
{
.sType = VK_STRUCTURE_TYPE_WRITE_DESCRIPTOR_SET,
.dstSet = 1,
.dstBinding = 0,
.dstArrayElement = 0,
.descriptorCount = 2,
.descriptorType = VK_DESCRIPTOR_TYPE_SAMPLED_IMAGE,
.pImageInfo = &textureInfos,
.pBufferInfo = nullptr,
};
在这段代码中,我们通过指定.dstSet = 1,将两个VkImageView对象绑定到了set 1上,并通过.dstBinding = 0绑定到了binding = 0上。
至于shader中的sampler[]和VertexBuffer我们就不再展示具体的过程了,大同小异。
最后,我们将所有的VkWriteDescriptorSet合并为一个数组,并调用vkUpdateDescriptorSet,更新资源与描述符集之间的关联
Passing resources to shader(binding descriptor sets)
我们前面已经提到过,使用vkUpdateDescriptorSet只是完成了资源的关联,我们还需要绑定描述符集,才能将资源传递给shader使用
Getting ready
我们将绑定描述符集的相关代码封装在VulkanCore::Pipeline::bindDescriptorSets()方法中
How to do it…
绑定描述符集,我们需要调用vkCmdBindDescriptorSets
1
2
3
4
5
6
7
8
VkCommandBuffer commandBuffer; // valid command buffer
VkPipelineLayout pipelineLayout; // valid pipeline layout
uint32_t set; // set number
VkDescriptorSet descriptorSet;
VkCmdBindDescriptorSets(
commandBuffer, VK_PIPELINE_BIND_POINT_GRAPHICS, pipelineLayout, set,
1u, &descriptorSet, 0, nullptr);
Updating push constants during rendering
与推送常量一样,当我们需要更新常量时,我们直接将值记录在对应的command buffer中
Getting ready
相关代码封装在VulkanCore::Pipeline:: udpatePushConstants()方法中
How to do it…
更新常量很简单,我们只需要调用vkCmdPushConstants即可
1
2
3
4
glm::vec4 vector; // constant
vkCmdPushConstants(
commandBuffer, pipelineLayout, VK_SHADER_STAGE_FRAGMENT_BIT, 0, sizeof(glm::vec4), &vectir);
Customizing shader behavior with specialization constants
编译着色器代码的过程一旦完成就具有不可变性。编译过程会带来大量的时间开销,通常在运行时会避免这种情况。即使对着色器进行微小的调整也需要重新编译,这会导致创建一个新的着色器模块,并可能需要创建一个新的管线——所有这些都需要大量的resource-intensive操作。
在Vulkan中,专用化常量能够允许我们在创建管线时,为shader参数指定常量值,而无需为了更新这些值时重新编译。
Getting ready
我们可以在结构体VulkanCore::Pipeline::GraphicsPipelineDescriptor中设置特化常量。对于每个使用特化常量的shader类型,我们需要一个VkSpecializationMapEntry的结构体。
How to do it…
在GLSL中,我们通过修饰符constant_id来声明特化常量
1
layout (constant_id = 0) const bool useShaderDebug = false;
当我们想要创建一个使用特化常量的管线时,我们首先将特化常量的值及其ID填充到VkSpecializationInfo结构体中。然后再把这个结构体传递给VkPipelineShaderStageCreateInfo。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
const bool kUseShaderDebug = false;
const VkSpecializationMapEntry useShaderDebug =
{
.constantID = 0,
.offset = 0,
.size = sizeof(bool),
};
const VkSpecializationInfo vertexSpecializationInfo =
{
.mapEntryCount = 1,
.pMapEntries = &useShaderDebug,
.dataSize = sizeof(bool),
.pData = &kUseShaderDebug,
};
const VkPipelineShaderStageCreateInfo info =
{
...
.pSpecializationInfo = &vertexSpecializationInfo,
};
Implementing MDI and PVP
MDI与PVP是现代图形API的特性,能够实现更高效灵活的顶点处理
MDI(Multiple Draw Indirect):允许我们使用单个命令发出多个draw call,其中每个draw call会从存储在设备中的buffer中获取参数(这也是被称为indirect的原因)。这个特性非常有用,因为这些参数可以由GPU自身修改。
PVP(programmable vertex pulling):每个着色器实例根据其索引和实例 ID 检索其顶点数据,而不是用顶点的属性进行初始化。这提供了灵活性,因为顶点属性及其格式不是固定在管线中的,并且可以仅基于着色器代码进行更改。
接下来,我们将分别展示如何实现MDI与PVP。
Implementing MDI
在MDI中,我们会将场景中所有的网格体数据存储两个较大的buffer中,其中一个用于存储所有的顶点,另一个用于存储所有的顶点索引。每个网格体的数据按照顺序存储。如下图所示:
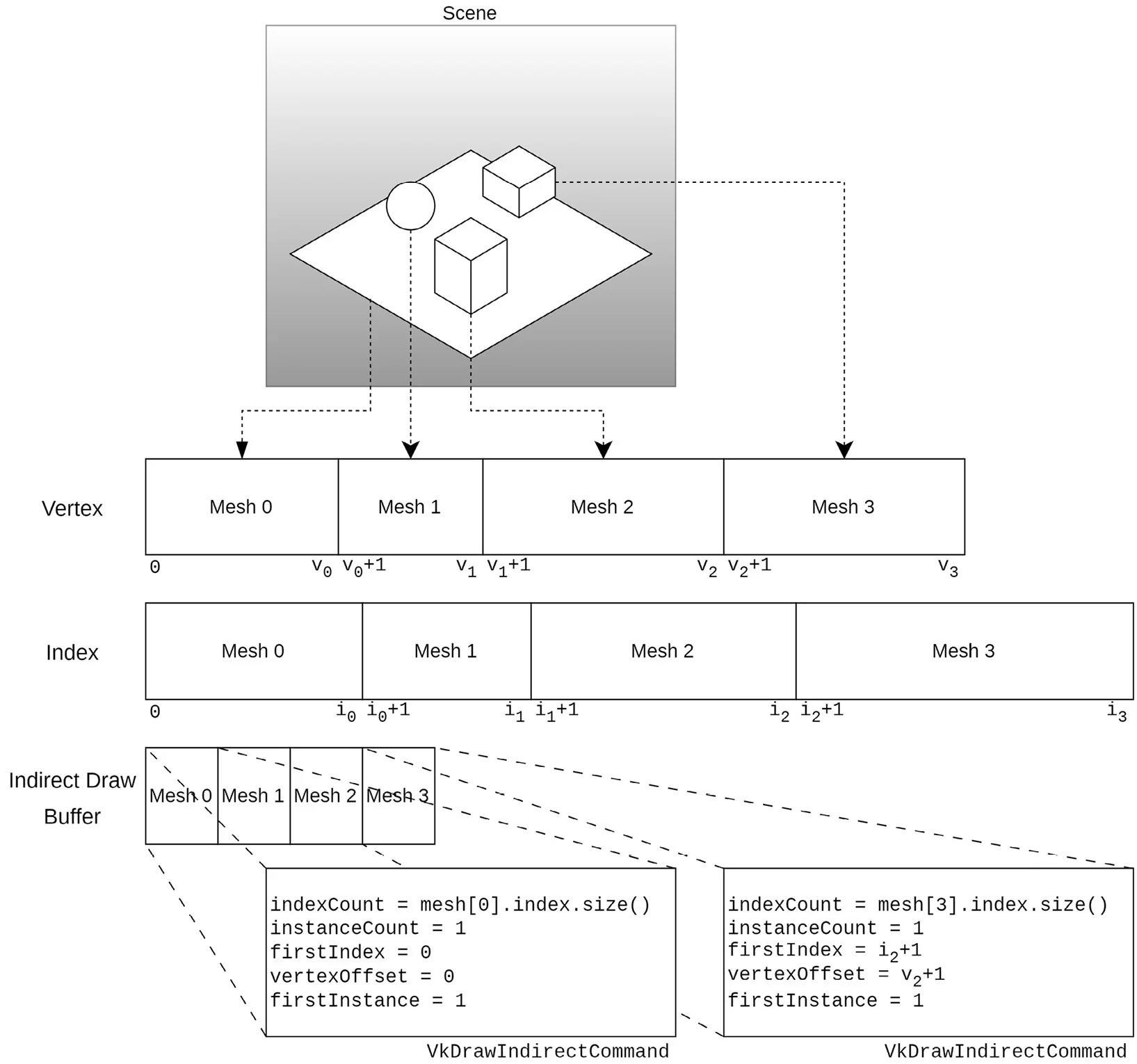
从图中我们也可以看到,绘制所需要的参数会存储在另一个buffer中,我们称为indirect draw buffer。并且存储时同样需要按照顺序,能够与网格体一一对应。