Modern Vulkan Cookbook第一章阅读笔记
本篇博客是《The Modern Vulkan Cookbook》的第一章的读书笔记。主要涵盖了Vulkan中的一些核心概念。
Vulkan Objects
在本小节,我们将会了解什么是Vulkan的对象,以及Vulkan对象之间是如何相互联系的。
Vulkan中的对象是一些“黑盒”的句柄,并且对象类型都以Vk为前缀命名,例如VkInstance,VkDevice。有些对象需要其他对象的实例来创建或分配。这种依赖关系为对象的创建建立了一种隐式的逻辑顺序。比方说,只有VkInstance对象创建后,我们才能创建VkPhysicalDevice对象。
下图总结了Vulkan中最重要的一些对象,以及它们之间的联系:
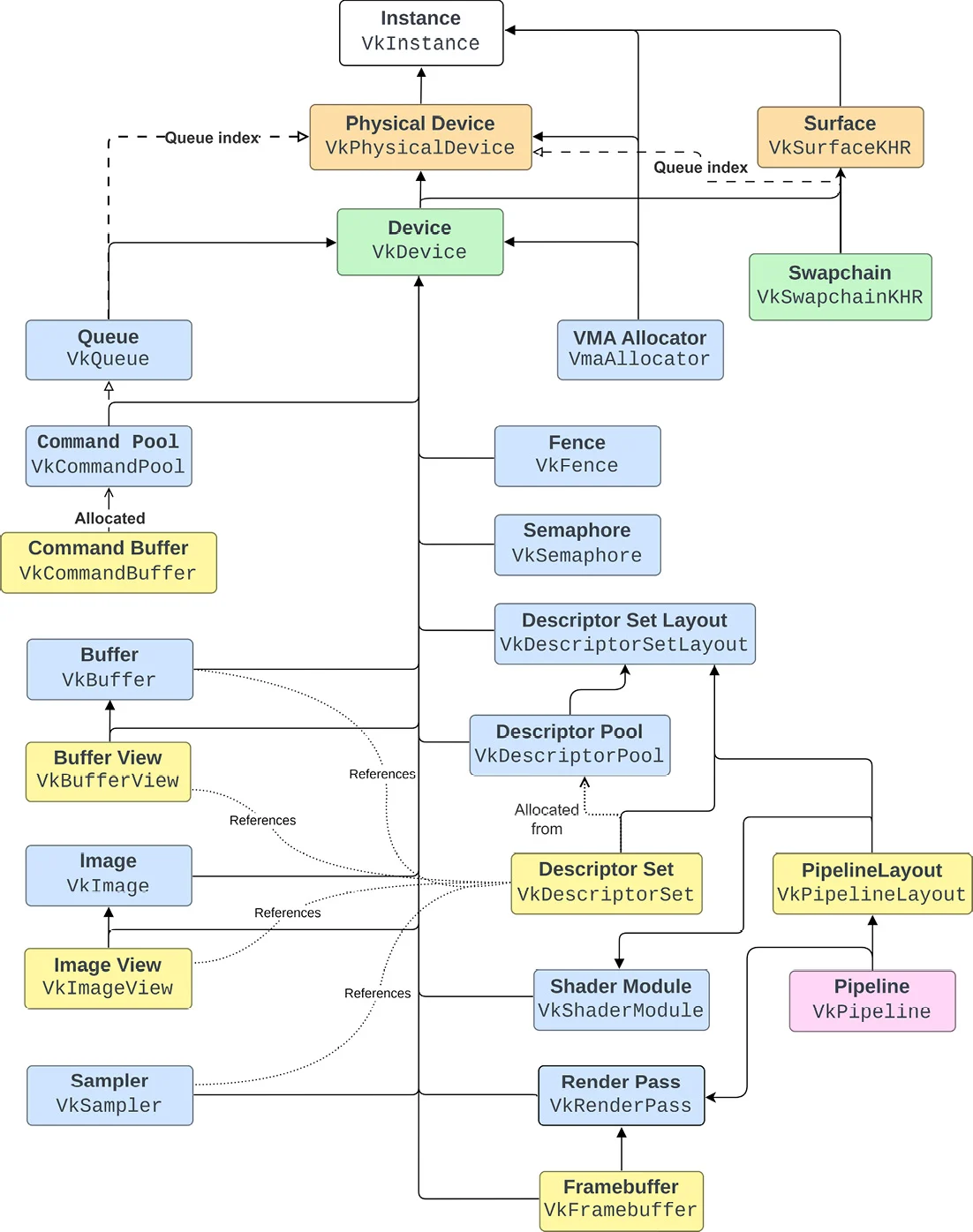
其中:
- 实线箭头表示显式的依赖关系:一个对象需要对其用实线箭头指向的对象进行引用。例如,
VkDevice需要VkPhysicalDevice的索引,而VkBufferView需要VkBuffer和VkDevice的索引。 - 虚线箭头表示隐式的依赖关系:以
VkQueue为例,一个VkQueue需要VkDevice的索引,但是并不显式地需要VkPhysicalDevice对象的索引。之所以说它们的关系是隐式的,是因为VkQueue只是一个队列族中的队列索引值,而队列族可以直接从VkPhysicalDevice枚举获得 - 对象可以从另一个对象中分配得到:如
VkCommandBuffer可以从VkCommandPool中分配得到
Vulkan Extensions
Vulkan高度依赖于扩展,也就是对Vulkan核心API功能和类型的补充。如下图所示: 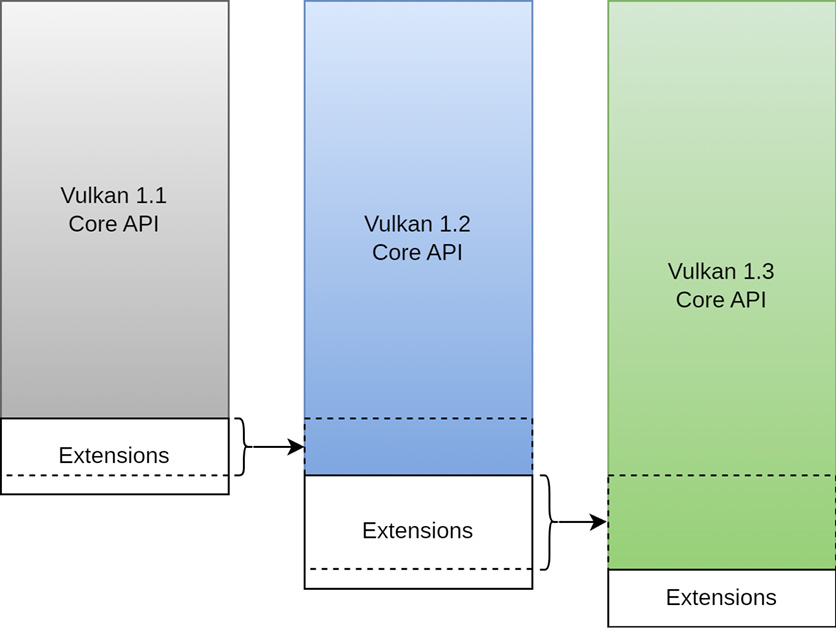
Getting ready
扩展可以分为两类,一种是实例级别的扩展,一种是设备级别的扩展。在使用一个扩展之前,我们需要在编译时确定该扩展是可用的。启用扩展时,需要我们提供对应的扩展名。
How to do it…
我们可以使用下面这样的代码来判断一个扩展是否可用
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
bool isEnabledForDevice(VkDevice device, const std::string &extName)
{
// std::unordered_map<std::string> deviceExtensions;
return deviceExtensions.contains(extName);
}
VkDevice device; // Valid Vulkan Device
#if defined(VK_KHR_win32_surface)
// VK_KHR_WIN32_SURFACE_EXTENSION_NAME is defined as the string
// "VK_KHR_win32_surface"
if (isEnabledForDevice(device, VK_KHR_WIN32_SURFACE_EXTENSION_NAME)) {
// VkWin32SurfaceCreateInfoKHR struct is available, as well as the
// vkCreateWin32SurfaceKHR() function
VkWin32SurfaceCreateInfoKHR surfaceInfo;
}
#endif
Vulkan Layer
Layer由Vulkan SDK提供,无需另外的配置工作。
Layer可以被插入到调用链中的Vulkan函数实现,能够拦截API的entry point,它有三个作用:
- 检测报错
- 评估性能
- 检测潜在的优化
Vulkan SDK提供了一些满足Plug and Play特性的layer,所以,我们只需要在Vulkan实例中启用需要的layer即可,layer在运行时调用Vulkan函数是时自行执行工作。
最重要的一个layer就是Validation Layer,它会验证所有的Vulkan函数调用以及对应的参数。此外,validation layer还会维护一个内部状态,用于确保我们的应用程序不会错过同步步骤,或者使用错误的图像layout。
Initializing the Vulkan Instance
VkInstance是我们要创建的第一个对象。它表示我们的应用程序与Vulkan运行时之间的链接,所以在应用程序中有且只有一个VkInstance。
VkInstance存储了使用Vulkan所需要的与应用程序相关(或者说特定于应用程序层面)的特定状态。因此,在创建VkInstance时,我们必须指定要启用的层(如Validation Layer)和扩展。
Creating a Surface
与OpenGL相同,将最终的渲染结果呈现到屏幕上需要窗口系统的支持,并且这个过程是与平台相关的。出于这个原因,Vulkan核心API并没有提供呈现渲染结果的功能,而是将相关的函数与类型以扩展的形式推出。在我们的系列博客中,我们不会涉及Windows平台以外的相关知识,所以我们需要使用到如下扩展:VK_KHR_surface,VK_KHR_swapchain以及VK_KHR_win32_surface
Getting ready
将渲染图像呈现到屏幕上,首先我们需要创建一个VkSurfaceKHR对象,它与操作系统的窗口系统接口相结合,在运行Vulkan程序时通过能够surface这个概念渲染图像。
此外,由于我们从物理设备中预留队列时需要使用到VkSurfaceKHR对象,所以VkSurfaceKHR的创建需要在VkInstance创建后以及VkPhysicalDevice创建前完成。
How to do it…
创建VkSurfaceKHR对象很简单,但是我们需要获取窗口系统的支持:
在Windows系统中,我们需要一个实例句柄
HINSTANCE和一个窗口句柄HWND。我们的系列博客使用了GLFW,所以这个步骤所轻松很多:1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
const auto window = glfwGetWin32Window(glfwWindow); #if defined(VK_USE_PLATFORM_WIN32_KHR) && \ defined(VK_KHR_win32_surface) if (enabledInstanceExtensions_.contains( VK_KHR_WIN32_SURFACE_EXTENSION_NAME)) { if (window != nullptr) { const VkWin32SurfaceCreateInfoKHR ci = { .sType = VK_STRUCTURE_TYPE_WIN32_SURFACE_CREATE_INFO_KHR, .hinstance = GetModuleHandle(NULL), .hwnd = (HWND)window, }; VK_CHECK(vkCreateWin32SurfaceKHR( instance_, &ci, nullptr, &surface_)); } } #endif
GLFW为我们封装了这个过程,我们可以通过下面的函数调用直接创建一个
VkSurfaceKHR对象:1
glfwCreateWindowSurface(instance, window, nullptr, &surface
Enumerating Vulkan Physical Devices
设备中可能存在多个支持Vulkan API的GPU,通常来说,我们需要只从中选择一个最能满足我们需求的设备即可。
调用vkEnumeratePhysicalDevices,我们能够从VkInstance中枚举出所有可用的物理设备,接着我们通过vkGetPhysicalDeviceProperties和vkGetPhysicalDeviceFeatures,分别检视给定物理设备所具有的属性与特性,判断是否能够满足我们的需求。最终筛选得到的VkPhysicalDevice将用于创建VkDevice和获取队列等后续操作。
Queue Families
在Vulkan中,一个物理设备可以有一个或多个队列族,每个队列族表示一组具有相似属性的队列,每个队列族支持一组特定的可以并行执行的操作或命令,如下图所示:
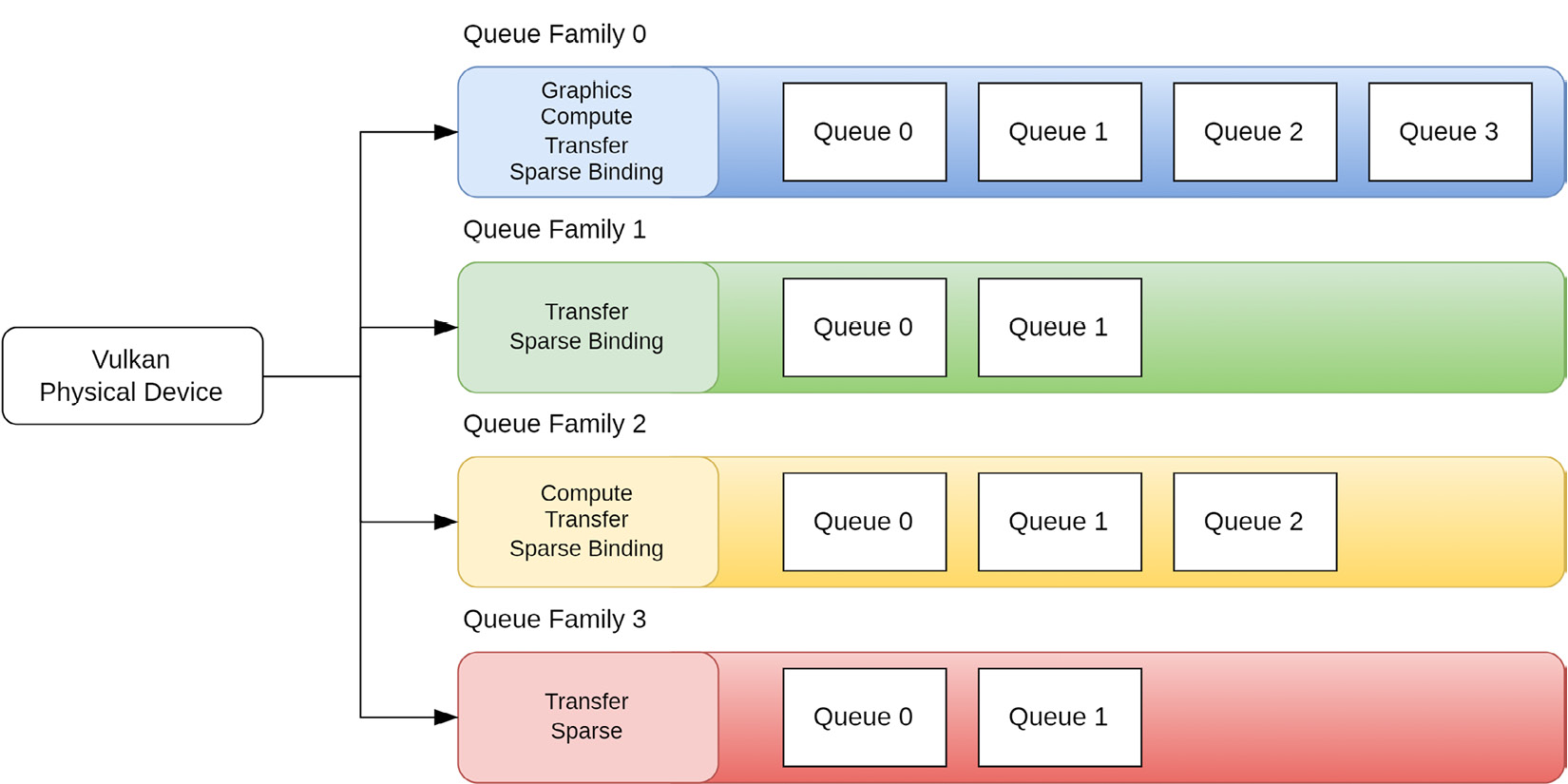
在创建VkDevice对象时,我们需要指定要使用的队列族,以及每个队列族中的队列数量。为了能够渲染并呈现渲染结果,我们通常需要至少一个负责执行图形指令的图形队列族。除此以外,我们还可能需要一个计算队列族用于执行计算工作载荷,以及一个传递队列族用于传递数据。
当我们创建好VkDevice对象后,我们还需要通过获取VkDevice对象所使用到的队列的句柄。当我们提交command buffer时,我们需要用到这些句柄。
Creating a Vulkan Logical Device
VkDevice对象是一个物理设备的逻辑上的表示方式,我们可以简要归纳出以下几点:
- 所有的图形与计算操作需要获取
VkDevice对象的引用 VkDevice可以通过队列来访问并获取GPU的功能,其中,队列用于向GPU提交命令,如绘制和传递内存数据- 通过
VkDevice,我们可以获取到一些其他的Vulkan对象,如管线,buffer,图像。
VkDevice几乎是Vulkan中最重要的一个对象,创建绝大多数的Vulkan对象都需要获取VkDevice的引用。
Creating a Command Pool
在Vulkan中,command buffer是一个容器,能够记录在GPU上执行的图形与计算命令。所以,当我们想要记录命令时,我们需要分配一个command buffer,然后使用vkCmd*这一族函数将命令记录下来。当记录完成后,我们就可以将command buffer提交给命令队列执行。
VkCommandPool是一个用于分配command buffer的命令池对象。该对象需要通过VkDevice对象创建,同时与一个特定的队列族相关联。
Allocating, Recording, and Submitting Commands
我们先简单梳理一下使用command buffer的过程:
- 通过
vkAllocateCommandBuffers从命令池中分配command buffer - 在记录命令前,我们需要调用
vkBeginCommandBuffer初始化command buffer - 记录完成后,我们需要调用
vkEndCommandBuffer,为提交command buffer做准备 - 通过
vkQueueSubmit将该command buffer提交到设备中以执行
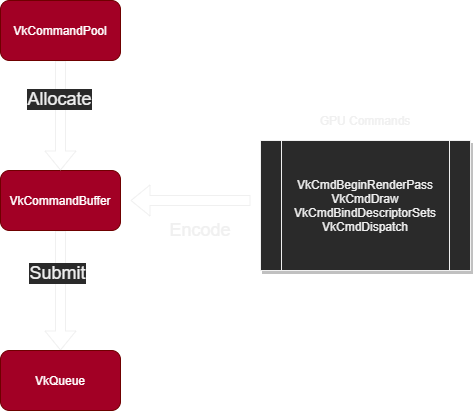
How to do it…
在调用
vkAllocateCommandBuffers时,我们需要提供对应的命令池,要分配的buffer的数量,指向存储command buffer属性的结构体的指针1 2 3 4 5 6 7 8 9 10 11
const VkCommandBufferAllocateInfo commandBufferInfo = { .sType = VK_STRUCTURE_TYPE_COMMAND_BUFFER_ALLOCATE_INFO, .commandPool = commandPool, // VK_COMMADN_BUFFER_LEVEL_PRIMARY表示该command buffer是主要的,可以直接提交给队列执行 // 与此相对的是次要的command buffer .level = VK_COMMADN_BUFFER_LEVEL_PRIMARY, .commandBufferCount = 1, }; VkCommandBuffer commandBuffer {VK_NULL_HANDLE}; VK_CHECK(vkAllocateCommandBuffer(device, &commandBufferInfo, &commandBuffer));
调用
vkBeginCommandBuffer时,我们需要提供一个指定command buffer的记录属性的结构体的指针1 2 3 4 5 6 7 8
const VkCommandBufferBeginInfo info = { .sType = VK_STRUCTURE_TYPE_COMMAND_BUFFER_BEGIN_INFO, // 这个flag表示该command buffer只会被提交一次,在提交后可以自动被释放或重置, // 有利于节省内存,提高性能 .flags = VK_COMMAND_BUFFER_USAGE_ONE_TIME_SUBMIT_BIT, }; VK_CHECK(vkBeginCommandBuffer(cmdBuffer, &info));
现在,我们就可以记录command buffer了,我们列举了一些常用的可以被记录的命令
vkCmdBindPipeline:将一个指定的图形或计算VkPipepline对象绑定到command buffer,以便后续的绘制或计算命令使用该管线vkCmdBindDescriptorSets:将指定的描述符集绑定到command buffer,描述符集存储了shader中所用到的缓存或图像资源。vkCmdBindVertexBuffers:将vertex buffer绑定到command buffer。vertex buffer存储了网格体的顶点数据vkCmdDraw:执行一次draw call,也就是处理顶点和光栅化的过程vkCmdDispatch:执行computer shadervkCmdCopyBuffer将一个buffer中的数据拷贝到另一个buffer中vkCmdCopyImage:将一个图像中的数据拷贝到另一个图像中
记录完成后,我们调用
vkEndCommandBuffer,为提交command buffer做准备:1
VK_CHECK(vkEndCommandBuffer(commandBuffer));
当记录完Command buffer后,Command buffer仍然存在于应用程序中,我们需要调用
vkQueueSubmit提交command buffer到GPU中执行1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
VkDevice device; // valiad device VkQueue queue; // valiad queue VkFence fence {VK_NULL_HANDLE}; const VkFenceCreateInfo fenceInfo = { .sType = VK_STRUCTURE_TYPE_FENCE_CREATE_INFO, .flags = VK_FENCE_CREATE_SIGNALED_BIT, }; VK_CHECK(vkCreateFence(device, &fenceInfo, nullptr, &fence)); const VkSubmitInfo submitInfo = { .sType = VK_STRUCTURE_TYPE_SUBMIT_INFO, .commandBufferCount = 1, .pCommandBuffers = commandBuffer, }; VK_CHECK(vkQueueuSubmit(queue, 1, submitInfo, fence));
在前面的代码中,我们使用到了VkFence,这是一个特定的Vulkan对象,用于实现GPU与CPU之间的同步。之所以用到VkFence,是因为VkQueueSubmit是一个异步的操作,并且不会阻塞应用程序。所以,一旦一个command buffer提交后,我们只能通过vkGetFenceStatus或vkWaitForFences等函数来检查VkFence对象的状态来判断执行的情况。我们会在后面进一步了解Vulkan中的同步与异步。
Reusing command buffers
我们将在本小节中了解,如何在重复使用command buffer的同时,避免应用程序与GPU之间的竞争。
command buffer的使用可以分为两种方法,我们分别讨论。
创建一个command buffer并不限期地重复使用。在这种情况中,一旦我们提交了command buffer,我们就需要等待它被处理完成,然后才能开始记录新的命令。而判断处理完成的方法是检查与其关联的VkFence的状态
1
2
3
VkDevice device; // valiad device
VK_CHECK(vkWaitForFences(device, 1, &fences, true, UINT32_MAX));
VK_CHECK(vkResetFences(device, 1, &fences));
下图演示了我们上述的这种方式,也就是创建一个command buffer,然后一直使用它记录命令并提交。可以从图中看到,如果我们不对同步进行干预,就可能导致GPU还在执行的过程中时,CPU就开始记录新的命令,从而导致了竞争的情况。
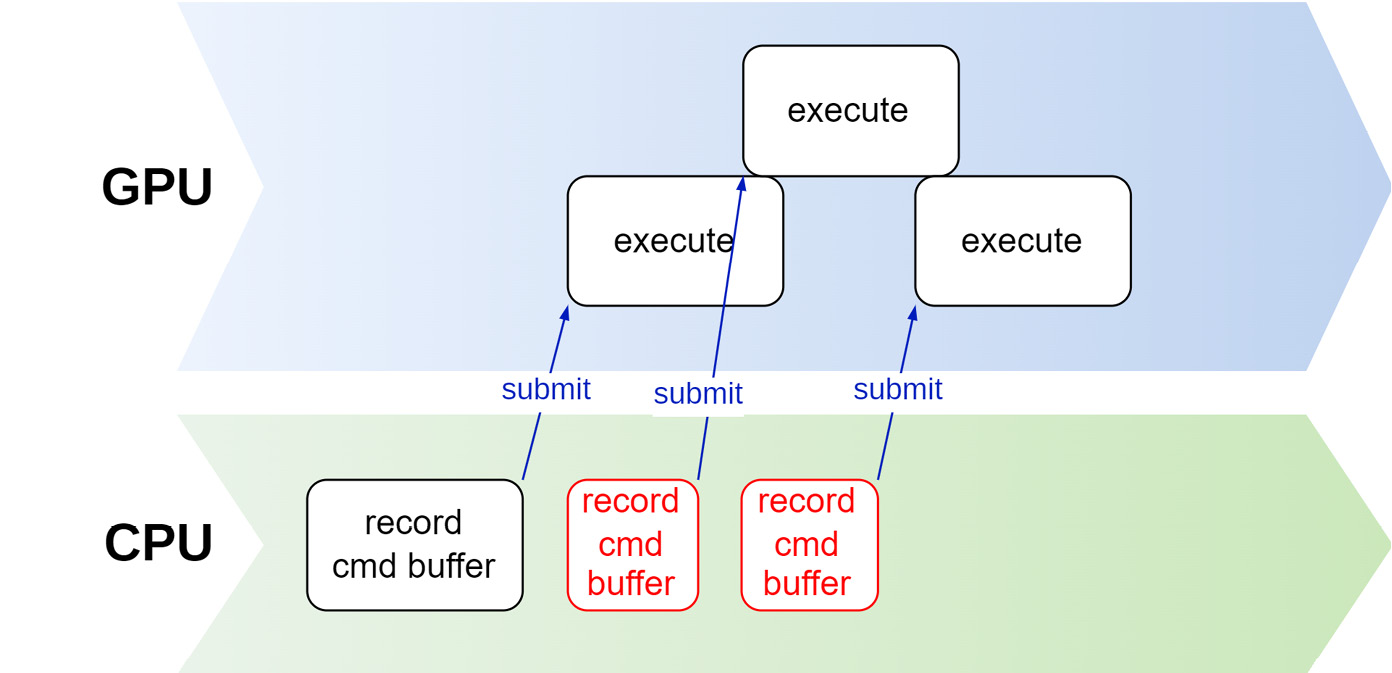
但是,这种情况可以通过使用VkFence得以避免。再重复使用一个command buffer之前,我们可以先检查与其关联的VkFence的状态,如下图所示:
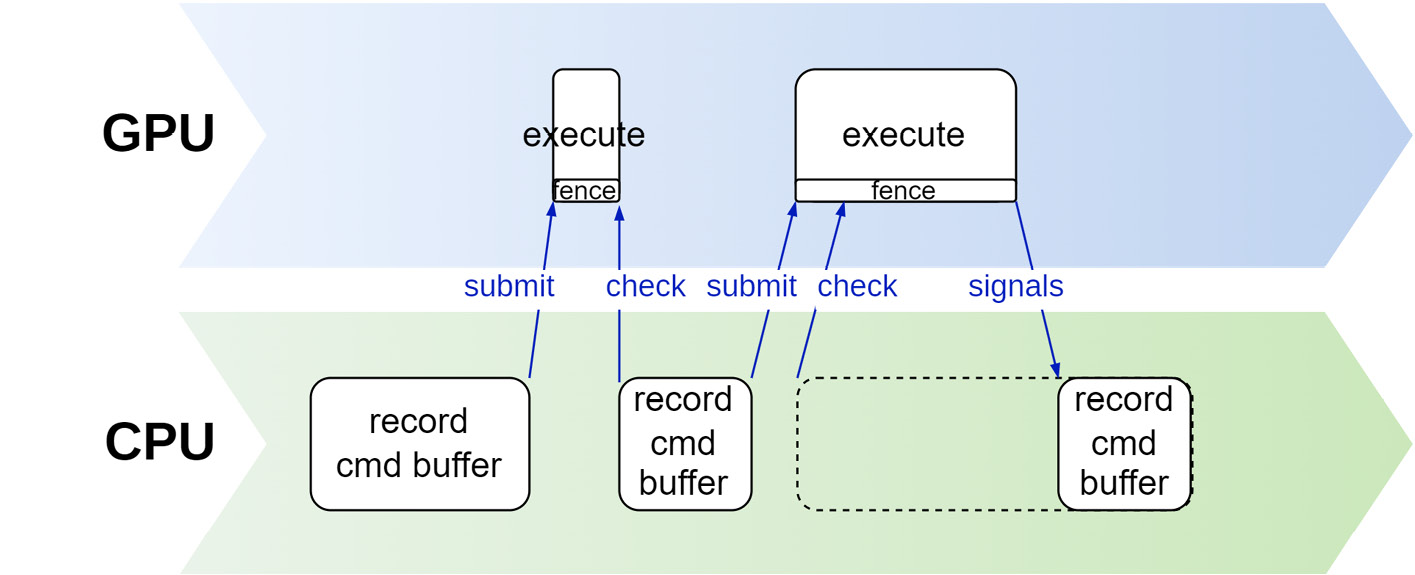
按需分配command buffer。这是最简单易行的方案,在这种情况下,我们需要在创建VkCommandPool时指定VK_COMMAND_POOL_CREATE_TRANSIENT_BIT这个标志。需要注意的是,在这种方案中,我们仍有可能需要使用一个关联的VkFence对象。
在我们的应用程序中,我们可以限制command buffer数量,有助于减少程序占用的内存。
Creating Render Passes
在Vulkan中,render pass是用于描述渲染过程的核心概念,它定义了渲染中的各种阶段、使用的附件、以及这些附件在渲染过程中如何读取和写入。其中,附件是在render pass中作为渲染目标的图像的引用,它包括颜色附件、深度附加和模板附件。下图展示了render pass对象所包含的内容:
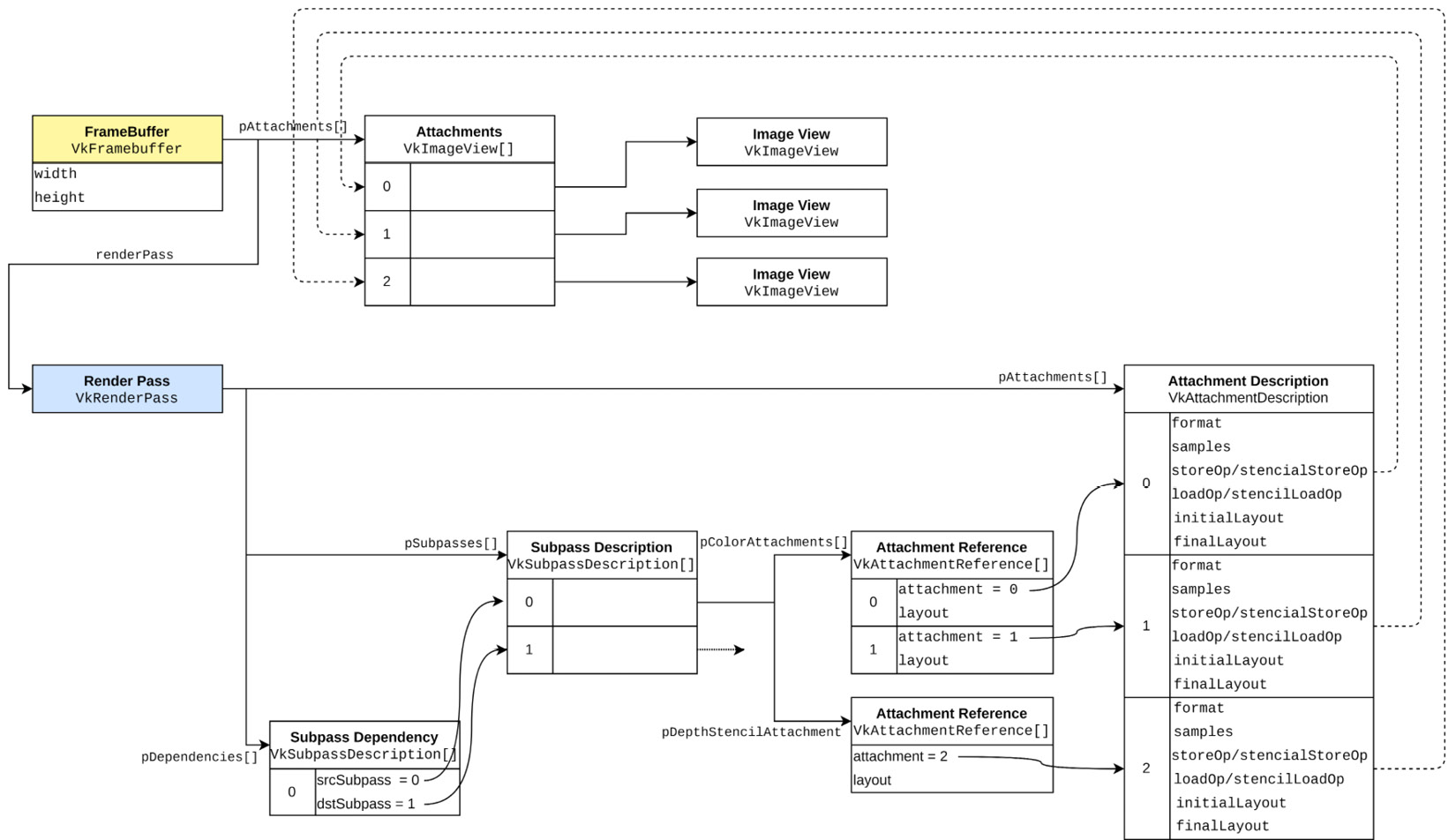
如图所示,创建VkRenderPass对象需要我们提供VkAttachmentDescription结构体,它定义了附件的多种属性,其中initialLayout和finalLayout在render pass的执行过程对优化附件的使用和布局转换起着至关重要的作用。在转换图像布局时,合理的initialLayout和finalLayout能够避免使用额外的管线屏障。比方说,颜色附件的initialLayout为VK_IMAGE_LAYOUT_UNDEFINED,在render pass的最后,这个颜色附件的finalLayout应该被转换为VK_IMAGE_LAYOUT_PRESENT_SRC_KHR。
子pass是render pass的一部分,用于执行一个特定的渲染操作。子pass的设计允许在同一渲染过程内进行不同的渲染操作。
我们会在子pass中加载附件,对其执行读取、写入等操作,最后在子pass结束时将其存储起来。其中,Vulkan对于载入和存储操作为我们提供了一些选项,这些选项定义了当载入和存储时应该如何处理附件中的内容,是清除还是dont care。选取合适的选项对于性能至关重要,例如,尽可能使用VK_ATTACHMENT_LOAD_OP_DONT_CARE和VK_ATTACHMENT_STORE_OP_DONT_CARE,能够避免额外的带宽使用。
子pass依赖关系描述了子pass之间的执行顺序以及相互之间的同步关系。
Vulkan支持render pass的兼容性,这允许为某个render pass创建的frame buffer可以被另一个兼容的render pass使用,从而提高资源利用率。兼容具体则要求,附件数量、格式,载入和存储操作、采样数量、布局匹配,对子pass的结构不作要求。
在本小节中,我们将了解如何创建一个render pass
Getting ready
创建render pass并不复杂,但是需要我们提供大量信息。我们可以将这些信息封装在VulkanCore::RenderPass这个类中,那么类的析构函数就会在适当时销毁对象,更容易管理
How to do it…
创建一个render pass,我们需要提供在render pass中使用到的附件,以及对应的载入和存储操作,最终的布局。此外,render pass必须与某个类型的管线绑定,包括图形管线和计算管线等,由VkPipelineBindPoint指定。以上就是VulkanCore::RenderPass这个类的构造函数所需要的全部参数。
构造函数会遍历传递进来的附件,为每个附件创建一个
VkAttachmentDescription结构体。该结构体包含了附件的一些基本信息(例如格式和初始布局),也会记录每个附件的载入和存储操作。同时,我们还会额外创建两个变量,分别存储颜色附件的引用和深度/模板附件的引用。1 2 3 4 5 6 7 8 9 10 11 12 13 14
RenderPass::RenderPass( const Context& context, const std::vector<std::shared_ptr<Texture>> attachments, const std::vector<VkAttachmentLoadOp>& loadOp, const std::vector<VkAttachmentStoreOp>& storeOp, const std::vector<VkImageLayout>& layout, VkPipelineBindPoint bindPoint, const std::string& name = "") : device(context.device) { std::vector<VkAttachmentDescription> attachmentDescriptors; std::vector<VkAttachmentReference> colorAttachmentReferences; std::optional<VkAttachmentReference> depthStencilAttachmentReference; }
对于每个附件,我们创建一个
VkAttachmentDescription结构体,并添加到attachmentDescriptors数组中1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
for (uint32_t index = 0; index < attachments.size(); index++) { attachmentDescriptors.emplace_back( VkAttachmentDescription { .format = attachment[index]->vkFormat(), .samples = VK_SAMPLE_COUNT_1_BIT, .loadOp = attachments[index].isStencil() ? VK_ATTACHMENT_LOAD_OP_DONT_CARE : loadOp[index], .storeOp = attachments[index].isStencil() ? VK_ATTACHMENT_STORE_OP_DONT_CARE : storeOp[index], .stencilLoadOp = attachments[index].isStencil() ? loadOp[index] : VK_ATTACHMENT_LOAD_OP_DONT_CARE, .stencilStoreOp = attachments[index].isStencil() ? storeOp[index] : VK_ATTACHMENT_STORE_OP_DONT_CARE, .initialLayout = attachments[index]->vkLayout(), .finalLayout = layout[index]. }); }
我们还需要判断附件的类型,是颜色附件还是深度/模板附件,我们需要创建对应的
VkAttachenmentReferece结构体1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
if (attachments[index]->isStencil() || attachments[index]->isDepth()) { depthStencilAttachmentReference = VkAttachmentReference { .attachment = index, .layout = VK_IMAGE_LAYOUT_DEPTH_STENCIL_ATTACHMENT_OPTIMAL, }; } else { colorAttachmentReferences.emplace_back( VkAttachmentReference { .attachment = index, .layout = VK_IMAGE_LAYOUT_COLOR_ATTACHMENT_OPTIMAL, }; ) }
目前简单起见,我们只创建一个子pass,它需要需要颜色附件的引用,和深度/模板附件的引用
1 2 3 4 5 6 7 8
const VkSubPassDescrioption spb = { .pipelineBindPoint = VK_PIPELINE_BIND_POINT_GRAPHICS, .colorAttachmentCount = static_cast<uint32_t>(colorAttachmentReferences.size()), .pColorAttachments = colorAttachmentReferences.data(), .pDepthStencilAttachment = depthStencilAttachmentReference.has_value() ? &depthStencilAttachmentReference.value() : nullptr, };
因为只有一个子pass,它只能且必须依赖与一个外部的子pass
1 2 3 4 5 6 7 8 9 10
const VkSubpassDependency subpassDependency= { .srcSubpass = VK_SUBPASS_EXTERNAL, .srcStageMask = VK_PIPELINE_STAGE_COLOR_ATTACHMENT_OUTPUT_BIT | VK_PIPELINE_STAGE_EARLY_FRAGMENT_TESTS_BIT, .dstStageMask = VK_PIPELINE_STAGE_COLOR_ATTACHMENT_OUTPUT_BIT | VK_PIPELINE_STAGE_EARLY_FRAGMENT_TESTS_BIT, .dstAccesMask = VK_ACCESS_COLOR_ATTACHMENT_WRITE_BIT | VK_ACCESS_DEPTH_STENCIL_ATTACHMENT_WRITE_BIT, };
最终,所有的相关信心都会被存储到
VkRenderPassCreateInfo中1 2 3 4 5 6 7 8 9 10 11 12 13 14
const VkRenderPassCreateInfo rpci = { .sType = VK_STRUCTURE_TYPE_RENDER_PASS_CREATE_INFO, .attachmentCount = static_cast<uint32_t>(attachmentDescriptors.size()), .pAttachments = attachmentDescritors.size(), .subpassCount = 1, .pSubpass = &spd, .dependencyCount = 1, .pDependencies = &subpassDependency, }; VK_CHECK(vkCreatRenderPass(device, &rpci, nullptr, &renderPass)); context.setVkObjectname(renderPass, VK_OBJECT_TYPE_RENDER_PASS, "Render Pass:" + name);
我们需要在类中的析构函数中,销毁render pass对象:
1 2 3 4
RenderPass:~RenderPass() { vkDestoryRenderPass(device, renderPass, nullptr); }
总结一下,render pass存储了关于如何处理附件(loaded, cleared, stored)的信息,并描述了子pass中的依赖关系。此外,render pass还描述了哪些是解析附件,这对于启用MSAA至关重要,我们会在后续的章节了解。
Creating framebuffers
在 Vulkan 中,VkFramebuffer 对象表示一个帧缓冲区,它是一个用于渲染的目标。帧缓冲区包含了一组VkImageView,这些VkImageView通常包括颜色附件、深度附件和模板附件。帧缓冲区与VkRenderPass一起使用,以定义渲染操作的输出目标。
Getting ready
我们将Vulkan的帧缓存对象封装在VulkanCore::Framebuffer类中
How to do it…
1
2
3
4
5
6
7
8
9
10
11
12
13
14
uint32_t width, height; // width and height of attachments
VkDevice device; // valid Vulkan device
std::vector<VkImageView> imageViews; // valid image views
const VkFramebufferCreateInfo framebufferCreateInfo =
{
.sType = VK_STRUCTURE_TYPE_FRAMEBUFFER_CREATE_INFO,
.renderPass = renderPass,
.attachmentCount = static_cast<uint32>(attachments.size()),
.pAttachments = imageViews.data(),
.width = attachments[0]->vkExtents().width(),
.height = attachments[0]->vkExtents().height(),
.layers = 1,
};
VK_CHECK(vkCreateFramebuffer(device, &framebufferCreateInfo, nullptr, &framebuffer));
创建帧缓存很简单。如果我们使用动态渲染,帧缓存也不再是严格必要的对象了。
Creating image views
在Vulkan中,我们通过VkImageView对象来指定图像应该被如何解释,以及图像如何被GPU访问。同时VkImageView定义了图像的格式、尺寸以及数据布局。
通过VkImageView,我们可以以各种方式使用图像,比如作为渲染命令的来源或目标,或者是着色器中的纹理。
Getting ready
我们将image view封装在VulkanCore::Texture中
How to do it…
在创建VkImageView时,我们需要获取对应的VkImage的句柄。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
VkImage image; // valid VkImage
const VkImageAspectFlags aspectMask = isDepth() ?
VK_IMAGE_ASPECT_DEPTH_BIT : VK_IMAGE_ASPECT_COLOR_BIT;
const VkImageViewCreateInfo imageViewInfo =
{
.sType = VK_STRUCTURE_TYPE_IMAGE_VIEW_CREATE_INFO,
.image = image,
.viewType = viewType,
.format = format,
.components =
{
.r = VK_COMPONENT_SWIZZLE_IDENTITY,
.g = VK_COMPONENT_SWIZZLE_IDENTITY,
.b = VK_COMPONENT_SWIZZLE_IDENTITY,
.a = VK_COMPONENT_SWIZZLE_IDENTITY,
},
.subsourceRange =
{
.aspectMaks = aspectMask,
.baseMipLevle = 0,
.levelCount = numMipLevels,
.baseArrayLayer = 0,
.layerCount = layers,
}
};
VK_CHECK(vkCreateImageView(context.device(), &imageViewInfo, nullptr, &imageView));
值得一提的是,image view可以覆盖整个图像,囊括图像的mip levels与层级,也可以只包含一个元素(单个mip level和单个层),甚至可以只覆盖图像的一部分。
The Vulkan graphics pipeline
图形管线是一个至关重要的概念,它描述了Vulkan应用程序中渲染图形的过程。图形管线包含了一系列阶段,每个阶段都有一个特定的目标,最终将3D场景转换为屏幕上的渲染图像。
下图展示了创建图形管线时可能需要填充的所有结构及其属性概览:
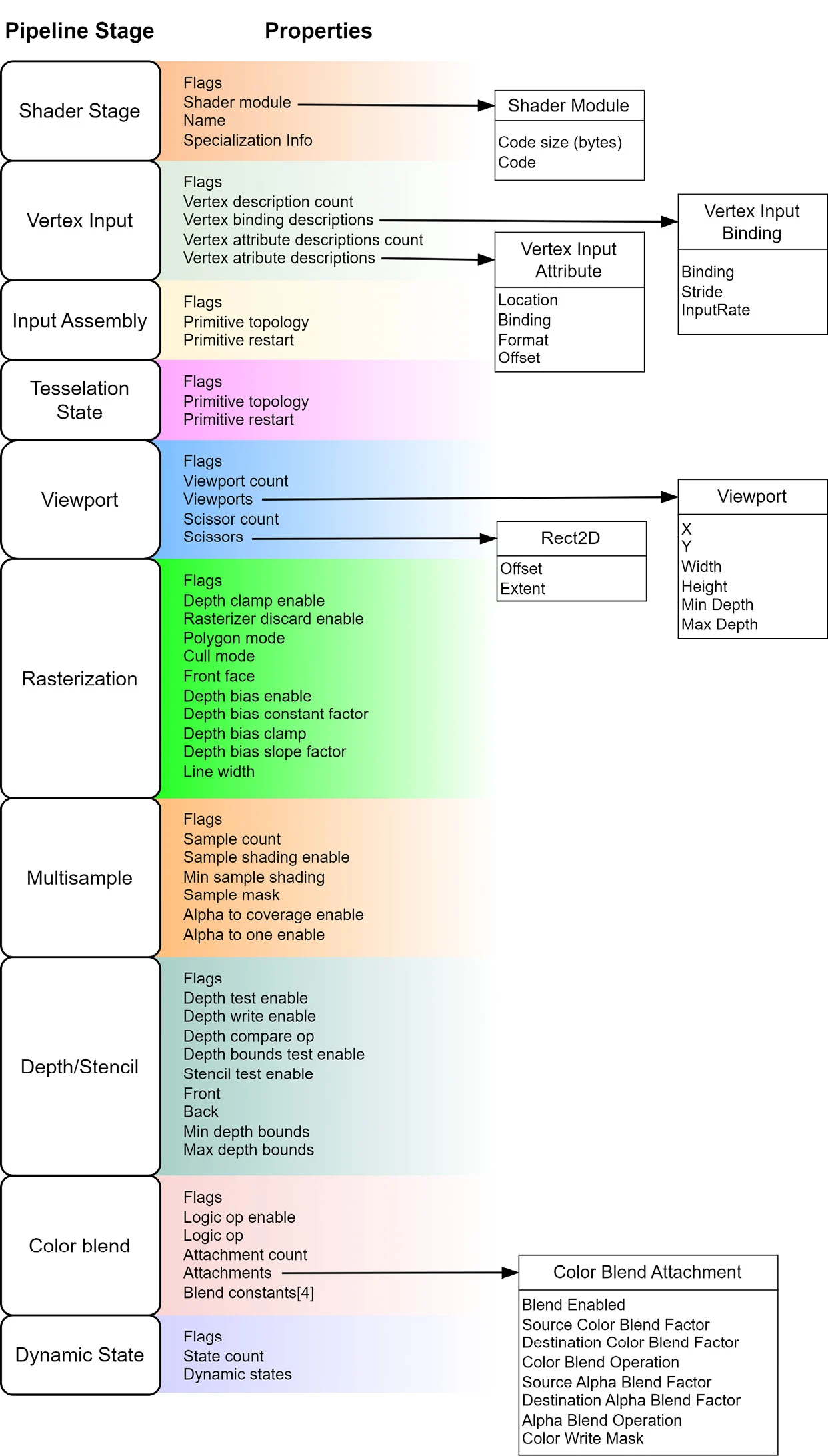
How to do it…
- 在Vulkan中,图形管线基本上是不可改变状态的对象,一旦完成创建,只有在某些特定情况下才能修改。当然,也有一些管线属性是可以在运行时动态修改的,如视口和剪裁窗口,我们将其成为动态状态dynamic states
- 需要说明的是,在本系列播客中,我们不会讨论管线中vertex input这一阶段,因为我们会使用Programable Vertex Pulling方法,在顶点着色器阶段中获取索引与顶点。
- 同样,管线布局是用于描述着色器所使用的资源的预期布局的结构体,在PVP方法中,我们会使用默认的管线布局。
Compiling shaders to SPIR-V
在OpenGL中,我们在运行时将GLSL编译为二进制文件,而Vulkan仅支持一种名为SPIR-V的中间表示方法,这是一种跨平台的,低级的中间表示,可以从各种着色器语言中生成。
在本小节中,我们将学习如何使用glslang库将GLSL编译为SPIR-V
Getting ready
在我们的系列博客中,我们实现了一个VulkanCore::ShaderModule类,用于封装shader。该类包含了ShaderModule::glslToSpirv方法,用于把GLSL编译为SPIR-V
How to do it…
我们来看一下函数ShaderModule::glslToSpirv的大致实现过程
调用
glslang::InitializeProcess()初始化glslang库,我们可以使用一个静态布尔变量判断是否是初始化已完成1 2 3 4 5 6 7 8 9 10 11 12 13
std::vector<char> ShaderModule::glslToSpirv( const std::vector<char>& data, EShLanguage shaderStage, const std::string& shaderDir, const char* entryPoint) { static bool glslangInitialized = false; if (!glslangInitialized) { glslang::InitializeProcess(); glslangInitialized = true; } }
TShader对象包含了要转换为SPIR-V的着色器以及其他各种参数,包括输入客户端的版本,GLSL的版本,和shader的entry point1 2 3 4 5 6 7 8 9
glslang::TShader tShader(shaderStage); const char* glslCStr = data.data(); tShader.setCStrings(&glslCStr, 1); glslang::EshTargetClientVersion clientVersion = glslang::EShTargetVulkan_1_3; glslang::EShTargetLanguageVersion langVersion = glslang::EShTargetSpv_1_3; tShader.setEnvInput(glslang::EShSourceGlsl, shaderStage, glslang::EShClientVulkan, 460); tshader.setEnvClient(glslang::EShClientVulkan, clientVersion); tshader.setEnvTarget(glslang::EShTargetSpv, langVersion); tshader.setSourceEntryPoint(entryPoint);
然后,我们收集系统中关于shader通常可用的资源限制,如纹理或顶点属性的最大数量,并确定编译器应该呈现的信息。最后,我们将shader编译到SPIRV并验证:
1 2 3 4 5
const TBuildInResource* resources = GetDefaultResources(); const EShMessages messages = static_cast<EShMessages>( EShMsgDefault | EShEShMsgSpvRules | EShMsgVulkanRules | EShMsgDebugInfo | EShMsgReadHlsl); CustomInclude include
…这一部分先忽略吧,与Vulkan API整体关联性不大
Dynamic states
前面我们提到,Vulkan中的图形管线整体是上不可变的,但是也存在一些在绘制时可变的对象,例如视口和剪裁矩形,线宽,混合常数,模版参考值等。
在不使用动态状态的情况下,我们的应用程序有如下几种选择:
- 在应用程序启动时创建管线
- 利用管线缓存
How to do it…
为了使用使用动态的参数,我们需要创建一个VkPipelineDynamicStateCreateInfo结构体实例,我们以视口为例:
1
2
3
4
5
6
7
const std::array<VkDynamicStatic, 1> dynamicStates = { VK_DYNAMIC_STATE_VIEWPORT };
const VkPipelineDynamicStateCreateInfo dynamicStateCreateInfo =
{
.sType = VK_STRUCTURE_TYPE_PIPELINE_DYNAMIC_STATE_CREATE_INFO,
.dynamicStateCount = static_cast<uint32_t>(dynamicStates.size()),
.pDynamicStates = dynamicStates.data(),
};
当我们创建图形管线时,我们需要将这个创建的实例提供给VkGraphiscPipelineCreateInfo
Creating a graphics pipeline
创建图像管线的过程很浅显易懂,我们只需要将所有需要的信息填充到VkGraphicsPipelineCreateInfo这个结构体中,然后调用vkCreateGraphicsPipelines即可。
我们将相关的代码都封装在VulkanCore::Pipeline类中,具体的代码就不再展示了
我们这里要额外说明一点,创建VkGraphicsPipeline对象是一步性能消耗较大的操作,我们可以为创建生成一个缓存,并在下次应用程序启动时重复利用。
Swapchain
Vulkan中的交换链对应了OpenGL中双重缓冲与三重缓冲的功能,同时在图像的配置、同步与呈现方面提供了更好的控制作用。
交换链同时是一个与VkSurfaceKHR相关联的图像的集合。在Vulkan中,用于创建和管理交换链的函数属于VK_KHR_swapchain扩展的一部分。
交换链中图像的数量必须在构建时确定,并且数量也需要在minImageCount和maxImageCount这两个值构成的区间中,这两个值可以从物理设备中的VkSurfaceCapabilitiesKHR中获取。
交换链中所使用的图像有交换链创建并管理,因为,这些图像的内存不会通过应用程序提供或分配。此外,VkImageView并不是由交换链对象所创建的,需要我们另外创建。
Getting ready
我们通过VulkanCore::Swapchain这个类来管理交换链
How to do it…
交换链扩展提供了一系列函数和类型,用于创建、管理和销毁交换链。 其中一些关键函数和类型如下:
vkCreateSwapchainKHR:用于创建VkSwapchain对象,需要提供VkSwapchainCreateInfoKHR这个结构体,它包含了关于surface的一些细节,如图像的数量、格式、尺寸、用法标志和一些其他的交换链属性vkGetSwapchainImagesKHR:在创建完交换链后,我们需要用此函数获取交换链中的图像的句柄,然后我们就可以为这些图像创建VkImageView和VkFramebuffer了vkAcquireNextImageKHR:用于从交换链中获取一个用于渲染的可用的图像。在调用此函数时,我们需要提供一个semaphore或fence,用于表示该图像已经准备好用于渲染vkQueuePresentKHR:当渲染完成后,我们可以用此函数将图像提交到显示设备上呈现vkDestroySwapchainKHR:负责销毁交换链,以及与其关联的资源
Understanding synchronization in the swapchain
应用程序和GPU进程是并行运行的。此外,除非我们指定,GPU上的command buffer以及命令也是并行运行的。为了能够确保CPU与GPU之间,以及GPU中正在被执行的command buffer之间的正确执行顺序,Vulkan提供了两种机制:fence和semaphore。前者用于同步GPU和CPU之间的工作,而后者则用于同步在GPU中执行的工作负载。
在本小节中,我们将了解为什么我们需要这两个同步机制,如何以及何时使用它们。
Getting ready
semaphore的使用被封装在VulkanCore::Swapchain中,fence的使用被封装在VulkanCore::CommandQueueManager中
How to do it…
fence和semaphore的用途和工作机制不同,我们逐一讨论。
如下图所示,如果没有使用fence,在CPU上运行的应用程序在向GPU提交命令时,会使得命令在GPU上立即开始执行。
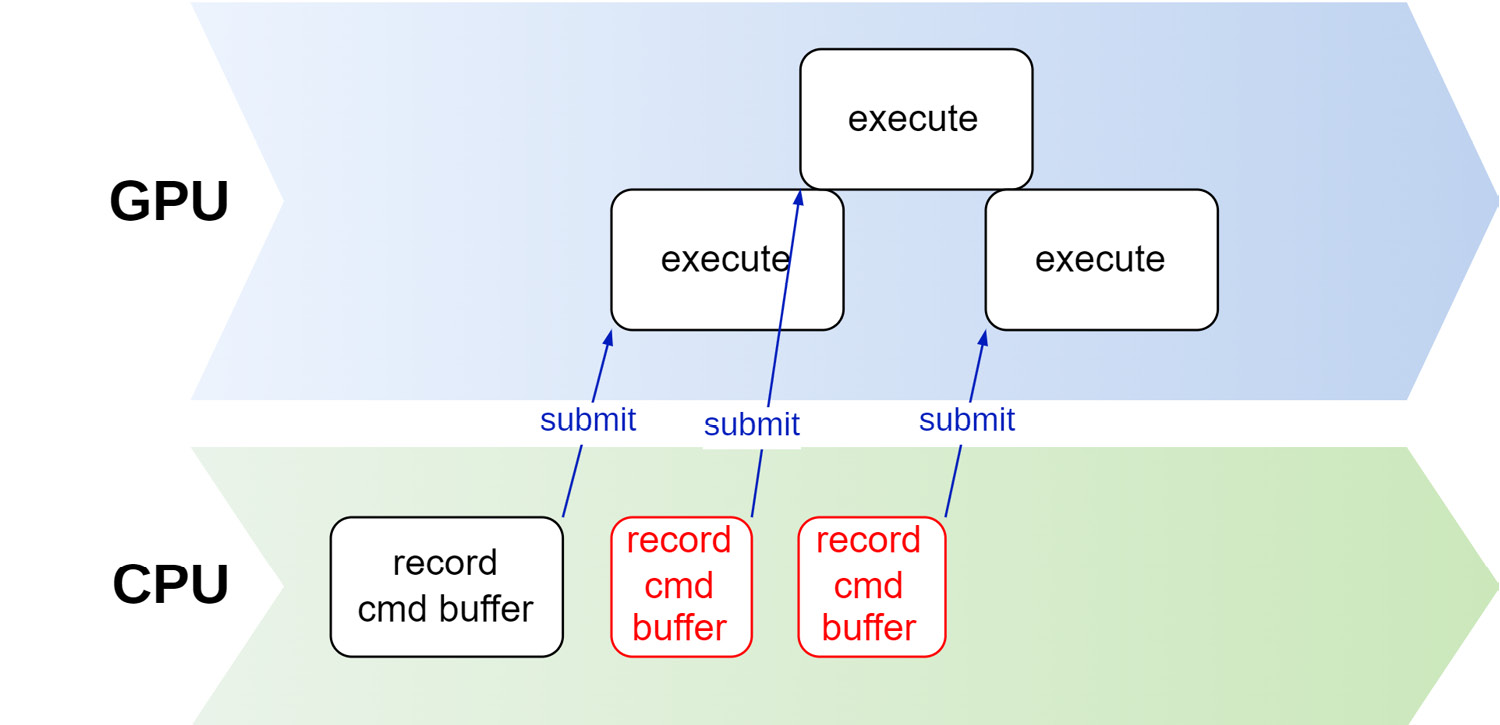
在绝大多数情况下,我们都希望等待GPU上的命令执行后再开始处理新的命令。当我们引入fence,我们就可以得到GPU上的命令何时处理完毕,如下图所示:
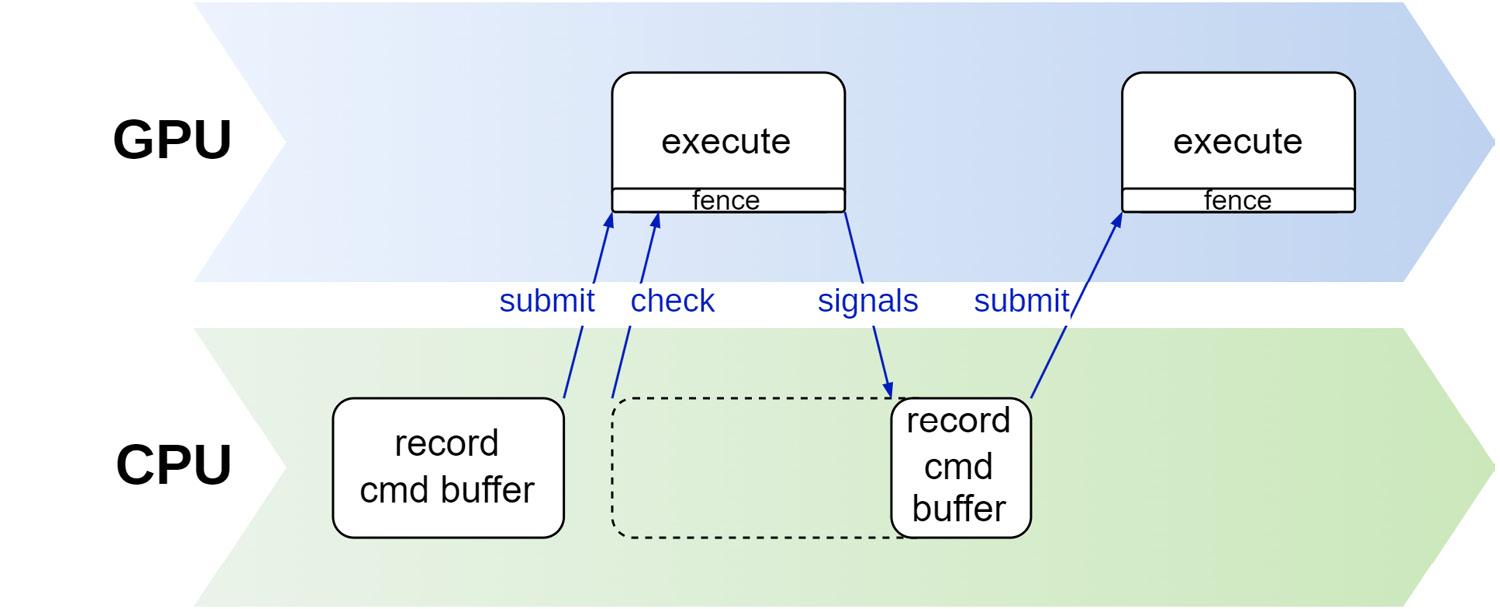
semaphore的工作机制类似,只是它负责处理GPU上运行的命令。下图展示了如何使用 Semaphore 来同步 GPU 上正在处理的命令。在提交缓冲区进行处理之前,应用程序负责创建信号传递器,并在命令缓冲区和信号传递器之间添加依赖关系。 一旦在 GPU 上处理完一个任务,就会发出信号给信号灯,下一个任务就可以继续进行。 这就强制规定了命令之间的顺
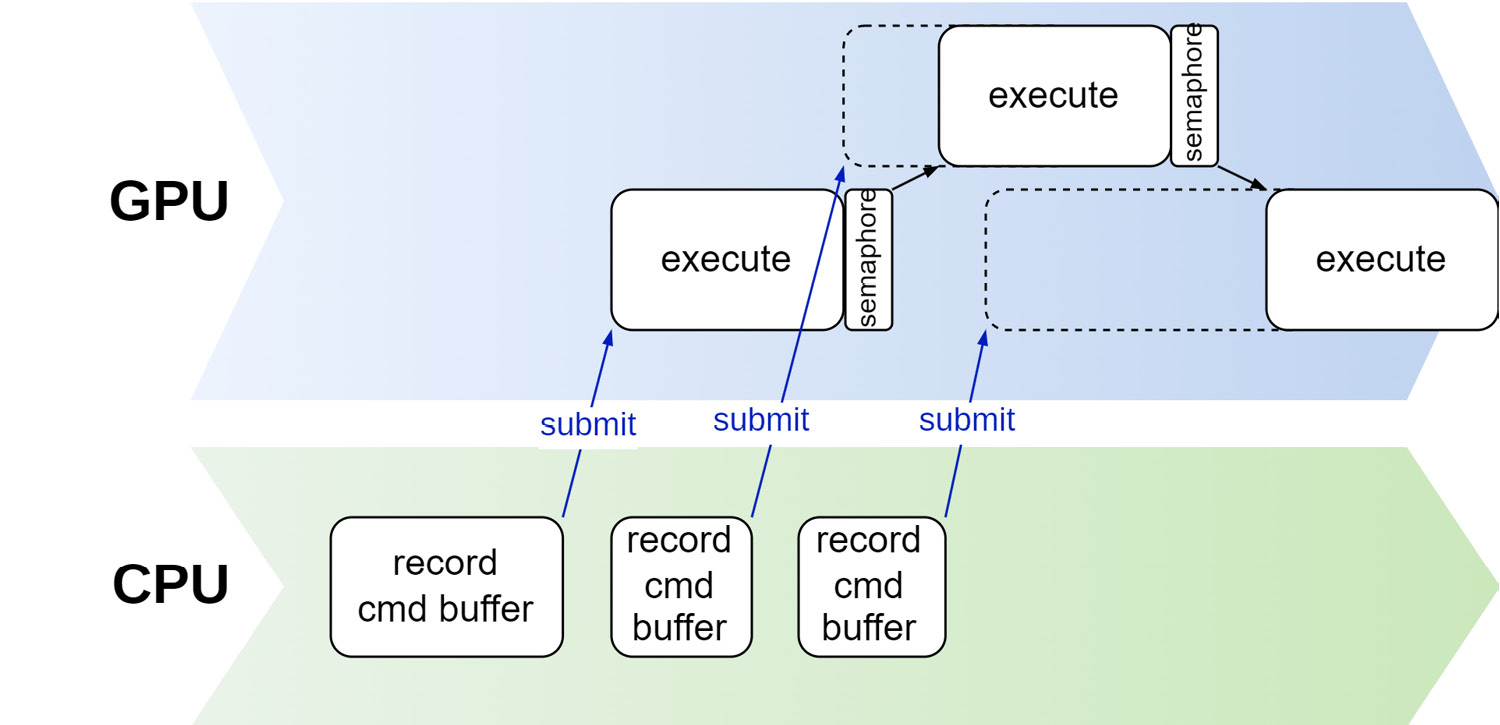
此外,获取图像,渲染图像以及呈现图像的过程都是异步的,我们需要为这三个步骤实现同步。具体的做法是使用两个semaphore原语。当获取的图像可用时,imageAvailable就会被标记为signaled,从而提示渲染指令开始处理,当渲染指令处理完毕,就会想另一个同步原语imageRendered发出信号,进而开始呈现图像。整个过程如下图所示:
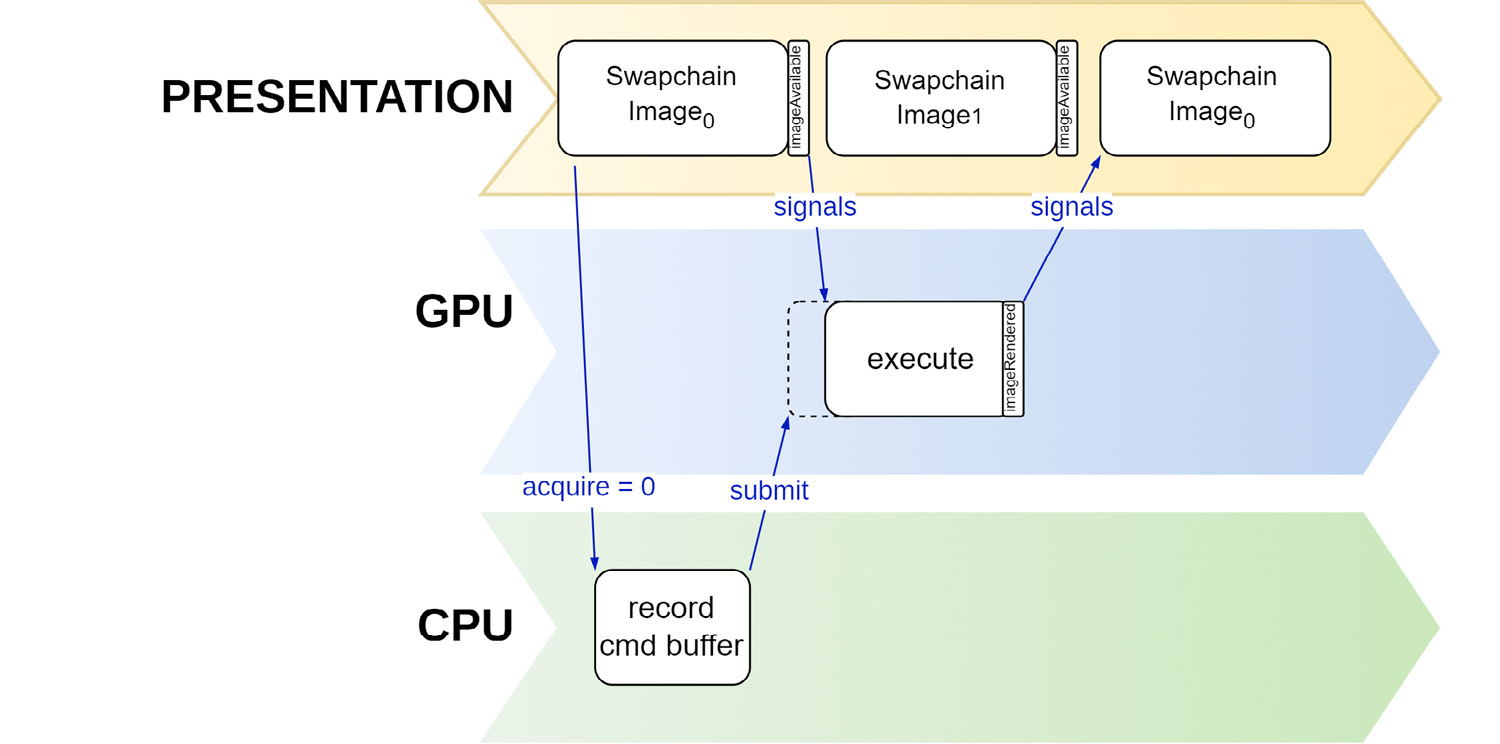
Populating submission information for presentation
我们前面提到过,提交一个command buffer需要一个VkSubmitInfo结构体的实例,该结构体允许我们指定等待(用于开始命令的执行进程)和发出信号(当command buffer执行结束后)的semaphore。通常情况下,这些semaphore是可选的,并不一定需要我们提供相应的信息。
但是,当提交用于将图像呈现在屏幕上的命令缓冲区时,这些信号量允许 Vulkan 将缓冲区的执行与呈现引擎同步。
Getting ready
VulkanCore::Swapchain类提供了一个helper函数,用于填充VkSubmitInfo结构体
How to do it…
1
2
3
4
5
6
7
8
9
10
11
12
const VkSubmitInfo submitInfo =
{
.sType = VK_STRUCTURE_TYPE_SUBMIT_INFO,
.waitSemaphore = 1,
.pWaitSemaphores = &imageAvailable,
.pWaitDstStageMask = submitStageMask,
.commandBufferCount = 1,
.pCommandBuffers = buffer,
.signalSemaphoreCount = 1,
.pSignaleSemaphores = &imagePresented,
};
VK_CHECK(vkQueueSubmit(mQueue, 1, &submitInfo, fence));
Presenting images
与OpenGL不同,在Vulkan中,将渲染图像呈现到屏幕上并非是一个自动的过程,我们需要调用VkQueuePresentKHR,同时提供一个VkPresentInfoKHR结构体的实例。
Getting ready
我们将呈现图像的相关代码写在VulkanCore::Swapchain::present()函数中
How to do it…
1
2
3
4
5
6
7
8
9
const VkPresentInfoKHR presentInfo{
.sType = VK_STRUCTURE_TYPE_PRESENT_INFO_KHR,
.waitSemaphoreCount = 1,
.pWaitSemaphores = &imageRendered_,
.swapchainCount = 1,
.pSwapchains = &swapchain_,
.pImageIndices = &imageIndex_,
};
VK_CHECK(vkQueuePresentKHR(presentQueue_, &presentInfo));
需要说明的是,当调用VkQueuePresentKHR后,图像并不会立即呈现,这个调用仅仅用于设置好同步机制,从而让Vulkan知道什么时机可以将图像呈现出来。