Introduction to Turing Mesh Shaders
本篇博客翻译自这篇英伟达的文章
Motivation
在常规的渲染管线中,难以实现高效地绘制数亿个三角形与数十万个对象。而在使用mesh shader的情况下,原本的mesh会被分割为更小的meshlets,每个meshlet在理想情况下优化了其内部的顶点复用,从而减少不必要的重复加载与顶点数据的处理,以提高图形渲染的效率。
比方说,用于CAD的数据可能包含了数千万到数亿个三角形,即使在进行遮挡剔除后,三角形的数量仍然很大。这种情况下,常规渲染管线中的一些固定步骤有可能带来不必要的负载:
- 即使拓扑结构没有改变,硬件的图元分配器每次也会通过扫描index buffer来创建vertex batch
- 对不可见的数据(背面、视锥体以外等)进行顶点以及属性提取
而mesh shader可以规避掉这些瓶颈。内存可以一次性读取到GPU中,并维持这种载入状态,直至程序结束。
mesh shader阶段会构建用于光栅化的三角形,但类似于compute shader,是在内部使用协同线程模型,而非单线程程序模型。在mesh shader之前的管线阶段是task shader,它的运作方式与细分类似,但同样使用协同线程模型。在传统的曲面细分与几何着色器中,线程只能用于特定的任务,具体的对比如下图所示:
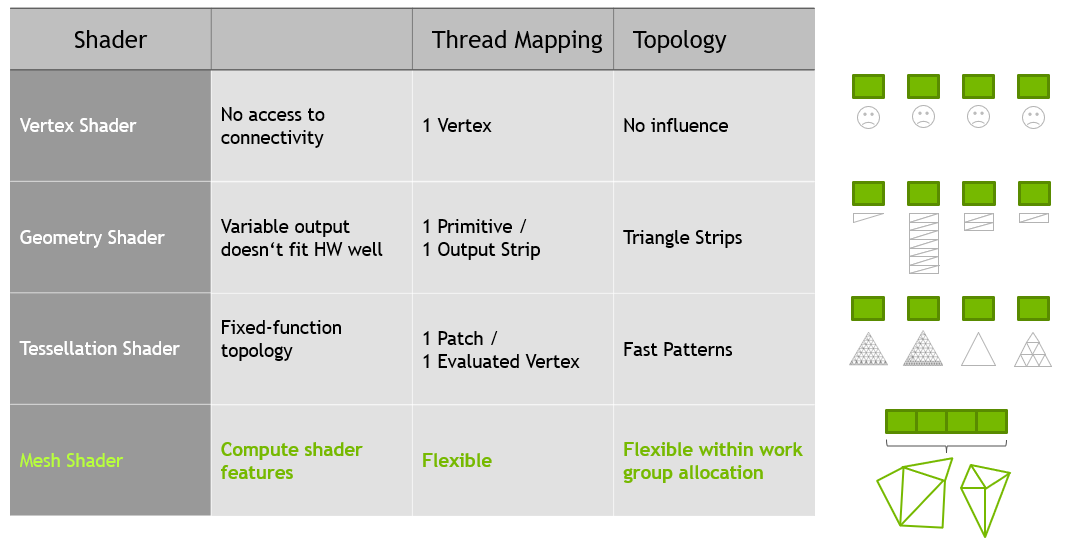
Mesh Shading Pipeline
在传统的管线中,我们需要获取属性,并执行vertex、tessellation、geometry shader。而新的管线包含了两个阶段:
- task shader:一个可编程的单元,在workgroup中操作,允许每个操作组发出或不发出mesh shader workgroup
- mesh shader:可编程单元,用于操作workgroup,产生primitive
我们可以从下图中了解到两种管线之间的区别:
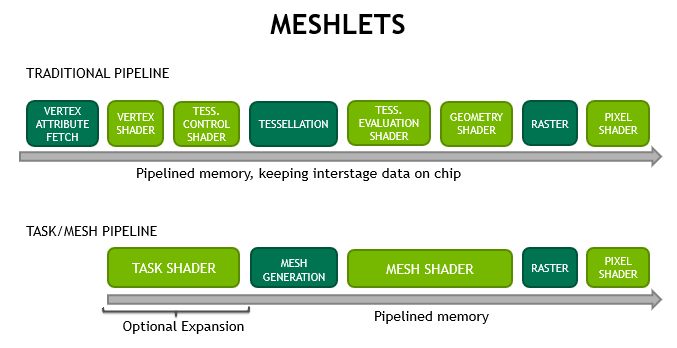
新的管线为开发者提供了多种特性:
- 更高的可扩展性:通过减少图元处理中的固定功能影响,借助着色器单元实现更高的可扩展性。现代 GPU 的通用用途使得更多种类的应用程序能够添加更多核心,并提高着色器的通用内存和算术性能。
- 带宽降低:因为顶点去重(顶点复用)可以预先完成,并在多个帧中重复使用。当前的 API 模型意味着硬件每次都必须扫描索引缓冲区。更大的网格小片意味着更高的顶点复用,也降低了带宽要求。此外,开发人员可以提出自己的压缩或程序生成方案。”
Meshlets and Mesh Shading
每个meshlet代表一个可变数量的顶点与图元。
我们将数量限制在64个顶点与126个图元。
本文由作者按照 CC BY 4.0 进行授权